class: center, middle, inverse, title-slide # Introdução aos Modelos Lineares ## com códigos em R ### <img src = 'https://d33wubrfki0l68.cloudfront.net/9b0699f18268059bdd2e5c21538a29eade7cbd2b/67e5c/img/logo/cursor1-5.png' width = '40%'> ### Maio de 2022 --- # Agenda .pull-left[ - O que é e quando usar - Parâmetro vs estimador - Teste de Hipóteses e valor-p - Interpretação dos parâmetros - Desempenho: EQM, EPR, AUC, Confusion Matrix - Outliers - Regressão Linear Múltipla - Preditores Categóricos - Transformações Não Lineares dos Preditores - Interações - Multicolinearidade - Fazendo Predições - Regressão Logística ] .pull-right[ #### Tópicos para próximos passos - Limitações da Regressão Linear - Sobreajuste (overfitting) - Regularização - LASSO e Seleção de Preditores - Validação Cruzada - Frameworks de Machine Learning ] --- # Ciência de dados <img src="static/img/ciclo-ciencia-de-dados.png" style = "display: block; margin-left: auto; margin-right: auto;" width = 70%> --- # Referências .pull-left[ <a href = "https://static1.squarespace.com/static/5ff2adbe3fe4fe33db902812/t/6062a083acbfe82c7195b27d/1617076404560/ISLR%2BSeventh%2BPrinting.pdf"> <img src="static/img/islr.png" style=" display: block; margin-left: auto; margin-right: auto;"></img> </a> ] .pull-right[ <a href = "https://web.stanford.edu/~hastie/Papers/ESLII.pdf"> <img src="static/img/esl.jpg" width = 44% style=" display: block; margin-left: auto; margin-right: auto;"></img> </a> ] --- # Referências .pull-left[ <a href = "https://r4ds.had.co.nz/"> <img src="static/img/r4ds.png" style=" display: block; margin-left: auto; margin-right: auto;"></img> </a> ] .pull-right[ <a href = "https://www.tmwr.org/"> <img src="static/img/tidymodels.png" width = 55% style=" display: block; margin-left: auto; margin-right: auto;"></img> </a> ] --- ## Referências - [Aprendizagem de Máquinas: Uma Abordagem Estatística (Rafael Izbicki e Thiago Mendonça, 2020)](http://www.rizbicki.ufscar.br/AME.pdf) - [Introduction to Statistical Learning (Hastie, et al)](https://hastie.su.domains/ISLR2/ISLRv2_website.pdf) - [Ciência de Dados: Fundamentos e Aplicações](https://curso-r.github.io/main-regressao-linear/referencias/Ci%C3%AAncia%20de%20Dados.%20Fundamentos%20e%20Aplica%C3%A7%C3%B5es.%20Vers%C3%A3o%20parcial%20preliminar.%20maio%20Pedro%20A.%20Morettin%20Julio%20M.%20Singer.pdf) --- class: middle, center, inverse # Introdução --- # Motivação Somos consultores e fomos contratados para dar conselhos para uma empresa aumentar as suas vendas. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-2-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Jornal tem mais retorno do que as demais mídias? Quantas vendas terão se eu investir X em jornais? --- # Motivação Somos consultores e fomos contratados para dar conselhos para uma empresa aumentar as suas vendas. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-3-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Jornal tem mais retorno do que as demais mídias? Quantas vendas terão se eu investir X em jornais? --- # Motivação - outro exemplo Somos da área de inadimplência e precisamos agir para assessorar clientes em situação iminente de atraso. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-4-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Qual tipo de contrato é o que me traz mais risco? --- # Motivação - outro exemplo Somos da área de inadimplência e precisamos agir para assessorar clientes em situação iminente de atraso. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-5-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Qual tipo de contrato é o que me traz mais risco? --- # Motivação - outro exemplo Somos da área de inadimplência e precisamos agir para assessorar clientes em situação iminente de atraso. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-6-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Qual tipo de contrato é o que me traz mais risco? --- # Motivação - outro exemplo Somos da área de inadimplência e precisamos agir para assessorar clientes em situação iminente de atraso. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-7-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Qual tipo de contrato é o que me traz mais risco? --- # Motivação - outro exemplo Somos da área de inadimplência e precisamos agir para assessorar clientes em situação iminente de atraso. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-8-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Qual tipo de contrato é o que me traz mais risco? --- # Motivação - outro exemplo Somos da área de inadimplência e precisamos agir para assessorar clientes em situação iminente de atraso. Obtivemos o seguinte banco de dados <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-9-1.png" style="display: block; margin: auto;" /> * PERGUNTA: Qual tipo de contrato é o que me traz mais risco? --- # Modo - Regressão e Classificação Existem dois principais tipos de problemas em modelagem estatística: .pull-left[ ## Regressão __Y__ é uma variável contínua. - Volume de vendas - Peso - Temperatura - Valor de Ações ] .pull-right[ ## Classificação __Y__ é uma variável categórica. - Fraude/Não Fraude - Pegou em dia/Não pagou - Cancelou assinatura/Não cancelou - Gato/Cachorro/Cavalo/Outro ] --- # Exemplo de reta de regressão <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-11-1.png" style="display: block; margin: auto;" /> --- # Exemplos de regressão logística <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-13-1.png" style="display: block; margin: auto;" /> --- # Definições e Nomenclaturas ### A tabela por trás (do excel, do sql, etc.) <table> <thead> <tr> <th style="text-align:left;"> midia </th> <th style="text-align:right;"> investimento </th> <th style="text-align:right;"> vendas </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> TV </td> <td style="text-align:right;"> 220.3 </td> <td style="text-align:right;"> 24.7 </td> </tr> <tr> <td style="text-align:left;"> newspaper </td> <td style="text-align:right;"> 25.6 </td> <td style="text-align:right;"> 5.3 </td> </tr> <tr> <td style="text-align:left;"> newspaper </td> <td style="text-align:right;"> 38.7 </td> <td style="text-align:right;"> 18.3 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 42.3 </td> <td style="text-align:right;"> 25.4 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 43.9 </td> <td style="text-align:right;"> 22.3 </td> </tr> <tr> <td style="text-align:left;"> TV </td> <td style="text-align:right;"> 139.5 </td> <td style="text-align:right;"> 10.3 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 11.0 </td> <td style="text-align:right;"> 7.2 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 1.6 </td> <td style="text-align:right;"> 6.9 </td> </tr> </tbody> </table> --- # Definições e Nomenclaturas * `\(X_1\)`, `\(X_2\)`, ..., `\(X_p\)`: variáveis explicativas (ou variáveis independentes ou *features* ou preditores). - `\(\boldsymbol{X} = {X_1, X_2, \dots, X_p}\)`: conjunto de todas as *features*. * __Y__: variável resposta (ou variável dependente ou *target*). * __Ŷ__: valor **esperado** (ou predição ou estimado ou *fitted*). * `\(f(X)\)` também é conhecida também como "Modelo" ou "Hipótese". ## No exemplo: - `\(X_1\)`: `midia` - indicadador de se a propaganda é para jornal, rádio, ou TV. - `\(X_2\)`: `investimento` - valor do orçamento * __Y__: `vendas` - qtd vendida --- # Definições e Nomenclaturas ### **Observado** *versus* **Esperado** - __Y__ é um valor **observado** (ou verdade ou *truth*) - __Ŷ__ é um valor **esperado** (ou predição ou estimado ou *fitted*). - __Y__ - __Ŷ__ é o resíduo (ou erro) Por definição, `\(\hat{Y} = f(x)\)` que é o valor que a função `\(f\)` retorna. <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-15-1.png" width="750" style="display: block; margin: auto;" /> --- # Definições e Nomenclaturas ### A tabela por trás depois das predições <table> <thead> <tr> <th style="text-align:left;"> midia </th> <th style="text-align:right;"> investimento </th> <th style="text-align:right;"> vendas </th> <th style="text-align:right;"> regressao_linear </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> TV </td> <td style="text-align:right;"> 220.3 </td> <td style="text-align:right;"> 24.7 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 17.8 </td> </tr> <tr> <td style="text-align:left;"> newspaper </td> <td style="text-align:right;"> 25.6 </td> <td style="text-align:right;"> 5.3 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 13.8 </td> </tr> <tr> <td style="text-align:left;"> newspaper </td> <td style="text-align:right;"> 38.7 </td> <td style="text-align:right;"> 18.3 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 14.4 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 42.3 </td> <td style="text-align:right;"> 25.4 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 15.0 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 43.9 </td> <td style="text-align:right;"> 22.3 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 15.1 </td> </tr> <tr> <td style="text-align:left;"> TV </td> <td style="text-align:right;"> 139.5 </td> <td style="text-align:right;"> 10.3 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 13.6 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 11.0 </td> <td style="text-align:right;"> 7.2 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 13.4 </td> </tr> <tr> <td style="text-align:left;"> radio </td> <td style="text-align:right;"> 1.6 </td> <td style="text-align:right;"> 6.9 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 12.9 </td> </tr> </tbody> </table> --- # Outro Exemplo: Classificação ### A tabela por trás (do excel, do sql, etc.) <table> <thead> <tr> <th style="text-align:left;"> tipo_de_contrato </th> <th style="text-align:right;"> valor_da_parcela </th> <th style="text-align:right;"> atrasou </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> padrao </td> <td style="text-align:right;"> 2692 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 1245 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> price </td> <td style="text-align:right;"> 2369 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 1571 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> padrao </td> <td style="text-align:right;"> 2349 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 1652 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> price </td> <td style="text-align:right;"> 2840 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 924 </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> --- # Outro Exemplo: Classificação * `\(X_1\)`, `\(X_2\)`, ..., `\(X_p\)`: variáveis explicativas (ou variáveis independentes ou *features* ou preditores). - `\(\boldsymbol{X} = {X_1, X_2, \dots, X_p}\)`: conjunto de todas as *features*. * __Y__: variável resposta (ou variável dependente ou *target*). * __Ŷ__: valor **esperado** (ou predição ou score ou *fitted*). * `\(f(X)\)` também é conhecida também como "Modelo" ou "Hipótese". ## No exemplo: - `\(X_1\)`: `tipo_de_contrato` - flags de se o contrato é padrao, price, ou revol. - `\(X_2\)`: `valor_da_parcela` - Valor da parcela do financiamento. * __Y__: `atrasou` - indicador de atraso maior que 30 dias na parcela. --- # Outro Exemplo: Classificação ### **Observado** *versus* **Esperado** - __Y__ é um valor **observado** (ou rótulo ou target ou verdade ou *truth*) - __Ŷ__ é um valor **esperado** (ou score ou probabilidade predita). - __log(Ŷ)__ ou __log(1-Ŷ)__ é o resíduo (ou erro) Por definição, `\(\hat{Y} = f(x)\)` que é o valor que a função `\(f\)` retorna. <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-18-1.png" width="750" style="display: block; margin: auto;" /> --- # Outro Exemplo: Classificação ### A tabela por trás depois das predições <table> <thead> <tr> <th style="text-align:left;"> tipo_de_contrato </th> <th style="text-align:right;"> valor_da_parcela </th> <th style="text-align:right;"> atrasou </th> <th style="text-align:right;"> regressao_logistica </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> padrao </td> <td style="text-align:right;"> 2692 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.98 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 1245 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.26 </td> </tr> <tr> <td style="text-align:left;"> price </td> <td style="text-align:right;"> 2369 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.98 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 1571 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.71 </td> </tr> <tr> <td style="text-align:left;"> padrao </td> <td style="text-align:right;"> 2349 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.88 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 1652 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.80 </td> </tr> <tr> <td style="text-align:left;"> price </td> <td style="text-align:right;"> 2840 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 1.00 </td> </tr> <tr> <td style="text-align:left;"> revol </td> <td style="text-align:right;"> 924 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;font-weight: bold;color: purple !important;"> 0.05 </td> </tr> </tbody> </table> --- # Por que ajustar uma f? * Predição * Inferência ## Predição Em muitas situações X está disponível facilmente mas, Y não é fácil de descobrir. (Ou mesmo não é possível descobrí-lo). Queremos que `\(\hat{Y} = \hat{f}(X)\)` seja uma boa estimativa (preveja bem o futuro). Neste caso não estamos interessados em como é a estrutura `\(\hat{f}\)` desde que ela apresente predições boas para `\(Y\)`. Por exemplo: * Meu cliente vai atrasar a fatura no mês que vem? --- # Por que ajustar uma f? * Predição * Inferência ## Inferência Em inferência estamos mais interessados em entender a relação entre as variáveis explciativas `\(X\)` e a variável resposta `\(Y\)`. Por exemplo: * A droga é eficaz para o tratamento da doença X? * **Quanto que é** o impacto nas vendas para cada real investido em TV? Neste material focaremos em **inferência**. --- # Por que ajustar uma f? <img src="static/img/usos_do_ml.png" style="display: block; margin-left: auto; margin-right: auto;" width=80%></img> --- class: letra ## O que é e quando usar .pull-left[ ### Regressão Linear Simples $$ y = \beta_0 + \beta_1x $$ ### Exemplo: $$ dist = \beta_0 + \beta_1speed $$ ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-20-1.png" style="display: block; margin: auto;" /> ] .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 61 (Simple Linear Regression). ] --- ## O que é e quando usar .pull-left[ ### Regressão Linear Simples $$ y = \beta_0 + \beta_1x $$ ### Exemplo: $$ dist = \beta_0 + \beta_1speed $$ ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-21-1.png" style="display: block; margin: auto;" /> ] .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 61 (Simple Linear Regression). ] --- ## O que é e quando usar .pull-left[ ### Regressão Linear Simples $$ y = \beta_0 + \beta_1x $$ ### Exemplo: $$ dist = \beta_0 + \beta_1speed $$ ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-22-1.png" style="display: block; margin: auto;" /> ] --- ## O que é e quando usar .pull-left[ ### Regressão Linear Simples $$ y = \beta_0 + \beta_1x $$ ] .pull-right[ ] ```r # ajuste de uma regressão linear simples no R *melhor_reta <- lm(dist ~ speed, data = cars) melhor_reta ``` ``` ## ## Call: ## lm(formula = dist ~ speed, data = cars) ## ## Coefficients: ## (Intercept) speed ## -17.579 3.932 ``` --- ## Métricas - "Melhor reta" segundo o quê? Queremos a reta que **erre menos**. Exemplo de medida de erro: **R**oot **M**ean **S**quared **E**rror. $$ RMSE = \sqrt{\frac{1}{N}\sum(y_i - \hat{y_i})^2} $$ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-24-1.png" style="display: block; margin: auto;" /> --- ## Métricas - "Melhor reta" segundo o quê? Queremos a reta que **erre menos**. Exemplo de medida de erro: **R**oot **M**ean **S**quared **E**rror. $$ RMSE = \sqrt{\frac{1}{N}\sum(y_i - (\hat{\beta_0} + \hat{\beta_1}x))^2} $$ Ou seja, nosso **objetivo** é ## Encontrar `\(\hat{\beta}_0\)` e `\(\hat{\beta}_1\)` que nos retorne o ~menor~ RMSE. --- ## Qual o valor ótimo para `\(\beta_0\)` e `\(\beta_1\)`? No nosso exemplo, a nossa **HIPÓTESE** é de que $$ dist = \beta_0 + \beta_1speed $$ Então podemos escrever o Erro Quadrático Médio como $$ EQM = \frac{1}{N}\sum(y_i - \hat{y_i})^2 = \frac{1}{N}\sum(y_i - \color{red}{(\hat{\beta}_0 + \hat{\beta}_1speed)})^2 $$ Com ajuda do Cálculo é possível mostrar que os valores ótimos para `\(\beta_0\)` e `\(\beta_1\)` são `\(\hat{\beta}_1 = \frac{\sum(x_i - \bar{x})(y_i - \bar{y})}{\sum(x_i - \bar{x})^2}\)` `\(\hat{\beta}_0 = \bar{y} - \hat{\beta}_1\bar{x}\)` .letrinha[ Já que vieram do EQM, eles são chamados de **Estimadores de Mínimos Quadrados**. ```r # lembrete: exercício 2 do script! ``` ] --- class: letra ## Depois de estimar... $$ \hat{y} = \hat{\beta}_0 + \hat{\beta}_1x $$ ### Exemplo: $$ \hat{dist} = \hat{\beta}_0 + \hat{\beta}_1speed $$ Colocamos um `\(\hat{}\)` em cima dos termos para representar "estimativas". Ou seja, `\(\hat{y}_i\)` é uma estimativa de `\(y_i\)`. .letrinha[ No nosso exemplo, - `\(\hat{\beta}_0\)` é uma estimativa de `\(\beta_0\)` e vale `-17.579`. - `\(\hat{\beta}_1\)` é uma estimativa de `\(\beta_1\)` e vale `3.932`. - `\(\hat{dist}\)` é uma estimativa de `\(dist\)` e vale `-17.579 + 3.932 x speed`. ```r # Exercício: se speed for 15 m/h, quanto que # seria a distância dist esperada? ``` ] --- class: letra ## Curiosidade - Método numérico Podemos encontrar a reta que **erre menos** por meio de algoritmos numéricos. Exemplo: Modelo de regressão linear `\(f(x) = \beta_0 + \beta_1 x\)`. <img src="static/img/0_D7zG46WrdKx54pbU.gif" style="position: fixed; width: 60%; "> .footnote[ Fonte: [https://alykhantejani.github.io/images/gradient_descent_line_graph.gif](https://alykhantejani.github.io/images/gradient_descent_line_graph.gif) ] --- ## Métricas - (Spoiler de Regressão Logística) Na regressão logística a estratégia é a mesma. Queremos a curva que **erre menos**. Exemplo: Modelo de regressão logística `\(f(x) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x)}}\)`. .pull-left[ <img src="static/img/gif_reg_logistica_otimizacao.gif" style="position: fixed; width: 35%; "> ] .pull-right[ Medida de Erro da Logística: `$$D = \frac{-1}{N}\sum[y_i \log\hat{y_i} + (1 - y_i )\log(1 - \hat{y_i})]$$` Em que `$$\hat{y}_i = f(x_i) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x_i)}}$$` ] --- ## Teste de Hipóteses e valor-p Exemplo: relação entre População Urbana e Assassinatos. .pull-left[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-27-1.png" style="display: block; margin: auto;" /> Modelo proposto: `$$y = \beta_0 + \beta_1 x$$` ] .pull-right-letrinha[ Hipótese do pesquisador: > "Assassinatos não estão relacionados com a proporção de população urbana de uma cidade." Tradução da hipótese em termos matemáticos: $$ H_0: \beta_1 = 0 \space\space\space\space\space vs \space\space\space\space H_a: \beta_1 \neq 0 $$ Se a hipótese for verdade, então o `\(\beta_1\)` deveria ser zero. Porém, os dados disseram que `\(\hat{\beta}_1 = 0.02\)`. #### 0.02 é diferente de 0.00? ] --- class: letrinha ## 0.02 é diferente de 0.00? Saída do R .letrinha[ ``` ## ## Call: ## lm(formula = Murder ~ UrbanPop, data = USArrests) ## ## Residuals: ## Min 1Q Median 3Q Max ## -6.537 -3.736 -0.779 3.332 9.728 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 6.41594 2.90669 2.207 0.0321 * *## UrbanPop 0.02093 0.04333 0.483 0.6312 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 4.39 on 48 degrees of freedom ## Multiple R-squared: 0.00484, Adjusted R-squared: -0.01589 ## F-statistic: 0.2335 on 1 and 48 DF, p-value: 0.6312 ``` ] --- class: letra ## 0.02 é diferente de 0.00? Conceito importante: Os estimadores ( `\(\hat{\beta}_0\)` e `\(\hat{\beta}_1\)` no nosso caso) têm distribuições de probabilidade. ### Simulação de 1000 retas (ajustadas com dados diferentes).  --- ## 0.02 é diferente de 0.00? Conceito importante: Os estimadores ( `\(\hat{\beta}_0\)` e `\(\hat{\beta}_1\)` no nosso caso) têm distribuições de probabilidade. ### A Teoria Assintótica nos fornece o seguinte resultado: .pull-left[ `\(t = \frac{\hat{\beta_1} - \beta_1}{\hat{\sigma}_{\beta_1}} \overset{\text{a}}{\sim} t(N - 2)\)` #### Em que `\(\hat{\sigma}_{\beta_1} = \sqrt{\frac{EQM}{\sum(x_i - \bar{x})^2}}\)` Usamos essas distribuições assintóticas para testar as hipóteses. ] .pull-right[ <div style="width:200px; height:100px"> <img src="static/img/dnorm_params.png"> </div> ] --- ## 0.02 é diferente de 0.00? Conceito importante: Os estimadores ( `\(\hat{\beta}_0\)` e `\(\hat{\beta}_1\)` no nosso caso) têm distribuições de probabilidade. ### A Teoria Assintótica nos fornece o seguinte resultado: .pull-left[ `\(t = \frac{\hat{\beta_1} - \beta_1}{\hat{\sigma}_{\beta_1}} \overset{\text{a}}{\sim} t(N - 2)\)` #### Em que `\(\hat{\sigma}_{\beta_1} = \sqrt{\frac{EQM}{\sum(x_i - \bar{x})^2}}\)` Usamos essas distribuições assintóticas para testar as hipóteses. ] .pull-right[ No nosso exemplo, a hipótese é `\(H_0: \beta_1 = 0\)`, então `$$t = \frac{0.02 - 0}{0.04} = 0.48$$` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-29-1.png" style="display: block; margin: auto;" /> ] --- ## 0.02 é diferente de 0.00? .letrinha[ Então agora podemos tomar decisão! Se a estimativa cair muito distante da distribuição t da hipótese 0, decidimos por **rejeitá-la**. Caso contrário, decidimos por **aceitá-la** como verdade. ] 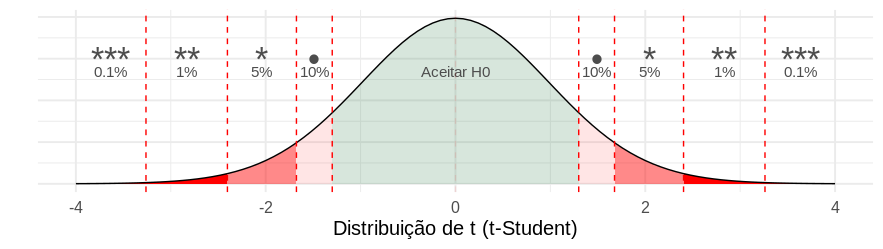 .letrinha[ ``` ## NO R: ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 6.41594 2.90669 2.207 0.0321 * ## UrbanPop 0.02093 0.04333 0.483 0.6312 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` ] --- ## Interpretação dos parâmetros .pull-left[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-31-1.png" style="display: block; margin: auto;" /> $$ y = \color{darkgblue}{\beta_0} + \color{darkgreen}{\beta_1}x $$ ] .pull-right-letrinha[ ### Interpretações matemáticas `\(\color{darkgblue}{\beta_0}\)` é o lugar em que a reta cruza o eixo Y. `\(\color{darkgreen}{\beta_1}\)` é a derivada de Y em relação ao X. É quanto Y varia quando X varia em 1 unidade. ### Interpretações estatísticas `\(\color{darkgblue}{\beta_0}\)` é a distância percorrida esperada quando o carro está parado (X = 0). `\(\color{darkgreen}{\beta_1}\)` é o efeito médio na distância por variar 1 ml/h na velocidade do carro. ] --- ## Teste de Hipóteses e valor-p ### Exercício 3 do script: No R, use a função `summary(melhor_reta)` (ver slide 9) para decidir se `speed` está associado com `dist`. Descubra o valor-p associado. lembrete: o banco de dados se chama `cars`. ### Exercício 4 do script: Interprete o parâmetro `\(\beta_1\)`. --- ## Intervalo de confiança para `\(\beta_1\)` #### Intervalo de 95% `$$[\hat{\beta} - 1,96 * \hat{\sigma}_{\beta_1}, \hat{\beta} + 1,96 * \hat{\sigma}_{\beta_1}]$$` #### Intervalo de 90% `$$[\hat{\beta} - 1,64 * \hat{\sigma}_{\beta_1}, \hat{\beta} + 1,64 * \hat{\sigma}_{\beta_1}]$$` #### Intervalo de 1 - `\(\alpha\)`% `$$[\hat{\beta}_1 - q_{\alpha} * \hat{\sigma}_{\beta_1}, \hat{\beta} + q_{\alpha} * \hat{\sigma}_{\beta_1}]$$` em que `\(q_\alpha\)` é o quantil da `\(Normal(0, 1)\)`. .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 66 (Assessing the Accuracy of the Model). ] --- ## O modelo está bom? ### EQM e EPR ERP significa *E*rro *P*adrão dos *R*esíduos e é definido como $$ EPR = \frac{\sum(y_i - \hat{y_i})^2}{N - 2} = \frac{SQR}{N - 2} $$ O **2** no denominador decorre do fato de termos **2 parâmetros** para estimar no modelo. - Se `\(y_i = \hat{y}_i \space\space\space \rightarrow \color{green}{EPR = 0 \downarrow}\)` - Se `\(y_i >> \hat{y}_i \rightarrow \color{red}{EPR = alto \uparrow}\)` - Se `\(y_i << \hat{y}_i \rightarrow \color{red}{EPR = alto \uparrow}\)` Problema: Como sabemos se o EPR é grande ou pequeno? .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 68 (Assessing the Accuracy of the Model). ] --- ## O modelo está bom? ### R-quadrado ( `\(R^2\)` ) $$ R^2 = 1 - \frac{\sum(y_i - \color{salmon}{\hat{y_i}})^2}{\sum(y_i - \color{royalblue}{\bar{y}})^2} = 1 - \frac{\color{salmon}{SQR}}{\color{royalblue}{SQT}} $$ .pull-left[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-32-1.png" style="display: block; margin: auto;" /> ] .pull-right[ `\(R^2 \approx 1 \rightarrow \color{salmon}{SQR} << \color{royalblue}{SQT}\)`. `\(R^2 \approx 0 \rightarrow \color{salmon}{reta} \text{ em cima da } \color{royalblue}{reta}\)`. Problema do `\(R^2\)` é que ele sempre aumenta conforme novos preditores vão sendo incluídos. ] .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 68 (Assessing the Accuracy of the Model). ] --- ## O modelo está bom? ### R-quadrado ajustado $$ R^2 = 1 - \frac{\color{salmon}{SQR}}{\color{royalblue}{SQT}}\frac{\color{royalblue}{N-1}}{\color{salmon}{N-p}} $$ Em que `\(p\)` é o número de parâmetros do modelo (no caso da regressão linear simples, `\(p = 2\)`). ```r # lembrete: exercícios 5 e 6 do script! ``` --- ## Outliers <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-34-1.png" style="display: block; margin: auto;" /> Resíduo = `\(y_i - \hat{y}_i\)` (observado - esperado). .letrinha[ ```r # lembrete: faça o exercício 7 do script ``` Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 96 (Outliers). ] --- ## Outliers <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-36-1.png" style="display: block; margin: auto;" /> Resíduo = `\(y_i - \hat{y}_i\)` (observado - esperado). .letrinha[ ```r # lembrete: faça o exercício 7 do script ``` ] .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 96 (Outliers). ] --- ## Outliers <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-38-1.png" style="display: block; margin: auto;" /> .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 96 (Outliers). ] --- ## Outliers <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-39-1.png" style="display: block; margin: auto;" /> .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 96 (Outliers). ] --- ## Outliers ### Distância de Cook .pull-left-letrinha[ A distância de Cook mede o efeito de excluir uma dada observação. `$$D_i = \frac{\sum_{j=1}^{n}(\hat{y}_j - \hat{y}_{j(i)})^2}{p EQM}$$` ```r modelo <- lm(dist ~ speed, data = cars) plot(modelo) cooks.distance(modelo) ``` ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-41-1.png" style="display: block; margin: auto;" /> ] .footnote[ Ver [Distância de Cook na Wikipedia](https://pt.wikipedia.org/wiki/Dist%C3%A2ncia_de_Cook). ] --- ## Outliers ### Diagnóstico - Visualização univariada (histograma, boxplot); - Comparação do valor com o desvio padrão; - Distância de Cook ### Tratamentos - Transformações log(), etc; - Categorização; - Remover os valores extremos (raramente boa ideia); --- class: letra # Regressão Linear Múltipla .pull-left[ ### Regressão Linear Simples $$ y = \beta_0 + \beta_1x $$ ### Exemplo: $$ dist = \beta_0 + \beta_1speed $$ ```r ### No R: lm(dist ~ speed, data=cars) ``` ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-43-1.png" style="display: block; margin: auto;" /> .letrinha[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 61 (Simple Linear Regression). ] ] --- class: letra # Regressão Linear Múltipla .pull-left[ ### Regressão Linear Múltipla $$ y = \beta_0 + \beta_1x_1 + \dots + \beta_px_p $$ ### Exemplo: $$ mpg = \beta_0 + \beta_1wt + \beta_2disp $$ ```r ### No R: lm(mpg ~ wt + disp, data=mtcars) ``` ] .pull-right[ <div id="htmlwidget-d1ba32e0541469b5ed49" style="width:504px;height:288px;" class="plotly html-widget"></div> <script type="application/json" data-for="htmlwidget-d1ba32e0541469b5ed49">{"x":{"visdat":{"da811f1d680":["function () ","plotlyVisDat"]},"cur_data":"da811f1d680","attrs":{"da811f1d680":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"x":{},"y":{},"z":{},"type":"scatter3d","mode":"markers","opacity":0.8,"inherit":true},"da811f1d680.1":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"z":[[28.6305259890832,28.3462919899241,28.062057990765,27.777823991606,27.4935899924469,27.2093559932878,26.9251219941288,26.6408879949697,26.3566539958106,26.0724199966515,25.7881859974925,25.5039519983334,25.2197179991743,24.9354840000153,24.6512500008562,24.3670160016971,24.082782002538,23.798548003379,23.5143140042199,23.2300800050608,22.9458460059018,22.6616120067427,22.3773780075836,22.0931440084245,21.8089100092655,21.5246760101064],[28.1063228739342,27.8220888747751,27.537854875616,27.253620876457,26.9693868772979,26.6851528781388,26.4009188789797,26.1166848798207,25.8324508806616,25.5482168815025,25.2639828823435,24.9797488831844,24.6955148840253,24.4112808848662,24.1270468857072,23.8428128865481,23.558578887389,23.27434488823,22.9901108890709,22.7058768899118,22.4216428907527,22.1374088915937,21.8531748924346,21.5689408932755,21.2847068941165,21.0004728949574],[27.5821197587852,27.2978857596261,27.013651760467,26.7294177613079,26.4451837621489,26.1609497629898,25.8767157638307,25.5924817646717,25.3082477655126,25.0240137663535,24.7397797671944,24.4555457680354,24.1713117688763,23.8870777697172,23.6028437705582,23.3186097713991,23.03437577224,22.7501417730809,22.4659077739219,22.1816737747628,21.8974397756037,21.6132057764447,21.3289717772856,21.0447377781265,20.7605037789674,20.4762697798084],[27.0579166436362,26.7736826444771,26.489448645318,26.2052146461589,25.9209806469999,25.6367466478408,25.3525126486817,25.0682786495227,24.7840446503636,24.4998106512045,24.2155766520454,23.9313426528864,23.6471086537273,23.3628746545682,23.0786406554092,22.7944066562501,22.510172657091,22.2259386579319,21.9417046587729,21.6574706596138,21.3732366604547,21.0890026612957,20.8047686621366,20.5205346629775,20.2363006638184,19.9520666646594],[26.5337135284871,26.2494795293281,25.965245530169,25.6810115310099,25.3967775318509,25.1125435326918,24.8283095335327,24.5440755343736,24.2598415352146,23.9756075360555,23.6913735368964,23.4071395377374,23.1229055385783,22.8386715394192,22.5544375402601,22.2702035411011,21.985969541942,21.7017355427829,21.4175015436239,21.1332675444648,20.8490335453057,20.5647995461466,20.2805655469876,19.9963315478285,19.7120975486694,19.4278635495104],[26.0095104133381,25.7252764141791,25.44104241502,25.1568084158609,24.8725744167018,24.5883404175428,24.3041064183837,24.0198724192246,23.7356384200656,23.4514044209065,23.1671704217474,22.8829364225883,22.5987024234293,22.3144684242702,22.0302344251111,21.7460004259521,21.461766426793,21.1775324276339,20.8932984284748,20.6090644293158,20.3248304301567,20.0405964309976,19.7563624318386,19.4721284326795,19.1878944335204,18.9036604343613],[25.4853072981891,25.20107329903,24.916839299871,24.6326053007119,24.3483713015528,24.0641373023938,23.7799033032347,23.4956693040756,23.2114353049165,22.9272013057575,22.6429673065984,22.3587333074393,22.0744993082803,21.7902653091212,21.5060313099621,21.221797310803,20.937563311644,20.6533293124849,20.3690953133258,20.0848613141668,19.8006273150077,19.5163933158486,19.2321593166895,18.9479253175305,18.6636913183714,18.3794573192123],[24.9611041830401,24.676870183881,24.392636184722,24.1084021855629,23.8241681864038,23.5399341872448,23.2557001880857,22.9714661889266,22.6872321897675,22.4029981906085,22.1187641914494,21.8345301922903,21.5502961931313,21.2660621939722,20.9818281948131,20.697594195654,20.413360196495,20.1291261973359,19.8448921981768,19.5606581990178,19.2764241998587,18.9921902006996,18.7079562015405,18.4237222023815,18.1394882032224,17.8552542040633],[24.4369010678911,24.152667068732,23.868433069573,23.5841990704139,23.2999650712548,23.0157310720957,22.7314970729367,22.4472630737776,22.1630290746185,21.8787950754595,21.5945610763004,21.3103270771413,21.0260930779822,20.7418590788232,20.4576250796641,20.173391080505,19.889157081346,19.6049230821869,19.3206890830278,19.0364550838687,18.7522210847097,18.4679870855506,18.1837530863915,17.8995190872325,17.6152850880734,17.3310510889143],[23.9126979527421,23.628463953583,23.344229954424,23.0599959552649,22.7757619561058,22.4915279569467,22.2072939577877,21.9230599586286,21.6388259594695,21.3545919603105,21.0703579611514,20.7861239619923,20.5018899628332,20.2176559636742,19.9334219645151,19.649187965356,19.3649539661969,19.0807199670379,18.7964859678788,18.5122519687197,18.2280179695607,17.9437839704016,17.6595499712425,17.3753159720834,17.0910819729244,16.8068479737653],[23.3884948375931,23.104260838434,22.8200268392749,22.5357928401159,22.2515588409568,21.9673248417977,21.6830908426387,21.3988568434796,21.1146228443205,20.8303888451614,20.5461548460024,20.2619208468433,19.9776868476842,19.6934528485252,19.4092188493661,19.124984850207,18.8407508510479,18.5565168518889,18.2722828527298,17.9880488535707,17.7038148544117,17.4195808552526,17.1353468560935,16.8511128569344,16.5668788577754,16.2826448586163],[22.8642917224441,22.580057723285,22.2958237241259,22.0115897249669,21.7273557258078,21.4431217266487,21.1588877274896,20.8746537283306,20.5904197291715,20.3061857300124,20.0219517308534,19.7377177316943,19.4534837325352,19.1692497333761,18.8850157342171,18.600781735058,18.3165477358989,18.0323137367399,17.7480797375808,17.4638457384217,17.1796117392626,16.8953777401036,16.6111437409445,16.3269097417854,16.0426757426264,15.7584417434673],[22.3400886072951,22.055854608136,21.7716206089769,21.4873866098178,21.2031526106588,20.9189186114997,20.6346846123406,20.3504506131816,20.0662166140225,19.7819826148634,19.4977486157043,19.2135146165453,18.9292806173862,18.6450466182271,18.3608126190681,18.076578619909,17.7923446207499,17.5081106215908,17.2238766224318,16.9396426232727,16.6554086241136,16.3711746249546,16.0869406257955,15.8027066266364,15.5184726274773,15.2342386283183],[21.8158854921461,21.531651492987,21.2474174938279,20.9631834946688,20.6789494955098,20.3947154963507,20.1104814971916,19.8262474980326,19.5420134988735,19.2577794997144,18.9735455005553,18.6893115013963,18.4050775022372,18.1208435030781,17.8366095039191,17.55237550476,17.2681415056009,16.9839075064418,16.6996735072828,16.4154395081237,16.1312055089646,15.8469715098056,15.5627375106465,15.2785035114874,14.9942695123283,14.7100355131693],[21.291682376997,21.007448377838,20.7232143786789,20.4389803795198,20.1547463803608,19.8705123812017,19.5862783820426,19.3020443828835,19.0178103837245,18.7335763845654,18.4493423854063,18.1651083862473,17.8808743870882,17.5966403879291,17.31240638877,17.028172389611,16.7439383904519,16.4597043912928,16.1754703921338,15.8912363929747,15.6070023938156,15.3227683946565,15.0385343954975,14.7543003963384,14.4700663971793,14.1858323980203],[20.767479261848,20.483245262689,20.1990112635299,19.9147772643708,19.6305432652117,19.3463092660527,19.0620752668936,18.7778412677345,18.4936072685755,18.2093732694164,17.9251392702573,17.6409052710982,17.3566712719392,17.0724372727801,16.788203273621,16.503969274462,16.2197352753029,15.9355012761438,15.6512672769847,15.3670332778257,15.0827992786666,14.7985652795075,14.5143312803485,14.2300972811894,13.9458632820303,13.6616292828712],[20.243276146699,19.95904214754,19.6748081483809,19.3905741492218,19.1063401500627,18.8221061509037,18.5378721517446,18.2536381525855,17.9694041534265,17.6851701542674,17.4009361551083,17.1167021559492,16.8324681567902,16.5482341576311,16.264000158472,15.979766159313,15.6955321601539,15.4112981609948,15.1270641618357,14.8428301626767,14.5585961635176,14.2743621643585,13.9901281651995,13.7058941660404,13.4216601668813,13.1374261677222],[19.71907303155,19.4348390323909,19.1506050332319,18.8663710340728,18.5821370349137,18.2979030357547,18.0136690365956,17.7294350374365,17.4452010382774,17.1609670391184,16.8767330399593,16.5924990408002,16.3082650416412,16.0240310424821,15.739797043323,15.4555630441639,15.1713290450049,14.8870950458458,14.6028610466867,14.3186270475277,14.0343930483686,13.7501590492095,13.4659250500504,13.1816910508914,12.8974570517323,12.6132230525732],[19.194869916401,18.9106359172419,18.6264019180829,18.3421679189238,18.0579339197647,17.7736999206056,17.4894659214466,17.2052319222875,16.9209979231284,16.6367639239694,16.3525299248103,16.0682959256512,15.7840619264921,15.4998279273331,15.215593928174,14.9313599290149,14.6471259298559,14.3628919306968,14.0786579315377,13.7944239323786,13.5101899332196,13.2259559340605,12.9417219349014,12.6574879357424,12.3732539365833,12.0890199374242],[18.670666801252,18.3864328020929,18.1021988029338,17.8179648037748,17.5337308046157,17.2494968054566,16.9652628062976,16.6810288071385,16.3967948079794,16.1125608088204,15.8283268096613,15.5440928105022,15.2598588113431,14.9756248121841,14.691390813025,14.4071568138659,14.1229228147069,13.8386888155478,13.5544548163887,13.2702208172296,12.9859868180706,12.7017528189115,12.4175188197524,12.1332848205933,11.8490508214343,11.5648168222752],[18.146463686103,17.8622296869439,17.5779956877848,17.2937616886258,17.0095276894667,16.7252936903076,16.4410596911486,16.1568256919895,15.8725916928304,15.5883576936713,15.3041236945123,15.0198896953532,14.7356556961941,14.4514216970351,14.167187697876,13.8829536987169,13.5987196995578,13.3144857003988,13.0302517012397,12.7460177020806,12.4617837029216,12.1775497037625,11.8933157046034,11.6090817054443,11.3248477062853,11.0406137071262],[17.622260570954,17.3380265717949,17.0537925726358,16.7695585734768,16.4853245743177,16.2010905751586,15.9168565759995,15.6326225768405,15.3483885776814,15.0641545785223,14.7799205793633,14.4956865802042,14.2114525810451,13.927218581886,13.642984582727,13.3587505835679,13.0745165844088,12.7902825852498,12.5060485860907,12.2218145869316,11.9375805877725,11.6533465886135,11.3691125894544,11.0848785902953,10.8006445911363,10.5164105919772],[17.098057455805,16.8138234566459,16.5295894574868,16.2453554583277,15.9611214591687,15.6768874600096,15.3926534608505,15.1084194616915,14.8241854625324,14.5399514633733,14.2557174642142,13.9714834650552,13.6872494658961,13.403015466737,13.118781467578,12.8345474684189,12.5503134692598,12.2660794701007,11.9818454709417,11.6976114717826,11.4133774726235,11.1291434734645,10.8449094743054,10.5606754751463,10.2764414759872,9.99220747682818],[16.573854340656,16.2896203414969,16.0053863423378,15.7211523431787,15.4369183440197,15.1526843448606,14.8684503457015,14.5842163465425,14.2999823473834,14.0157483482243,13.7315143490652,13.4472803499062,13.1630463507471,12.878812351588,12.594578352429,12.3103443532699,12.0261103541108,11.7418763549517,11.4576423557927,11.1734083566336,10.8891743574745,10.6049403583155,10.3207063591564,10.0364723599973,9.75223836083824,9.46800436167917],[16.0496512255069,15.7654172263479,15.4811832271888,15.1969492280297,14.9127152288707,14.6284812297116,14.3442472305525,14.0600132313934,13.7757792322344,13.4915452330753,13.2073112339162,12.9230772347572,12.6388432355981,12.354609236439,12.0703752372799,11.7861412381209,11.5019072389618,11.2176732398027,10.9334392406437,10.6492052414846,10.3649712423255,10.0807372431664,9.79650324400737,9.5122692448483,9.22803524568923,8.94380124653016],[15.5254481103579,15.2412141111989,14.9569801120398,14.6727461128807,14.3885121137216,14.1042781145626,13.8200441154035,13.5358101162444,13.2515761170854,12.9673421179263,12.6831081187672,12.3988741196081,12.1146401204491,11.83040612129,11.5461721221309,11.2619381229719,10.9777041238128,10.6934701246537,10.4092361254947,10.1250021263356,9.84076812717651,9.55653412801743,9.27230012885836,8.98806612969929,8.70383213054022,8.41959813138115]],"x":[1.513,1.66944,1.82588,1.98232,2.13876,2.2952,2.45164,2.60808,2.76452,2.92096,3.0774,3.23384,3.39028,3.54672,3.70316,3.8596,4.01604,4.17248,4.32892,4.48536,4.6418,4.79824,4.95468,5.11112,5.26756,5.424],"y":[71.1,87.136,103.172,119.208,135.244,151.28,167.316,183.352,199.388,215.424,231.46,247.496,263.532,279.568,295.604,311.64,327.676,343.712,359.748,375.784,391.82,407.856,423.892,439.928,455.964,472],"type":"surface","opacity":0.9,"inherit":true}},"layout":{"margin":{"b":40,"l":60,"t":25,"r":10},"scene":{"xaxis":{"title":"wt"},"yaxis":{"title":"disp"},"zaxis":{"title":"mpg"}},"hovermode":"closest","showlegend":false,"legend":{"yanchor":"top","y":0.5}},"source":"A","config":{"modeBarButtonsToAdd":["hoverclosest","hovercompare"],"showSendToCloud":false},"data":[{"x":[2.62,2.875,2.32,3.215,3.44,3.46,3.57,3.19,3.15,3.44,3.44,4.07,3.73,3.78,5.25,5.424,5.345,2.2,1.615,1.835,2.465,3.52,3.435,3.84,3.845,1.935,2.14,1.513,3.17,2.77,3.57,2.78],"y":[160,160,108,258,360,225,360,146.7,140.8,167.6,167.6,275.8,275.8,275.8,472,460,440,78.7,75.7,71.1,120.1,318,304,350,400,79,120.3,95.1,351,145,301,121],"z":[21,21,22.8,21.4,18.7,18.1,14.3,24.4,22.8,19.2,17.8,16.4,17.3,15.2,10.4,10.4,14.7,32.4,30.4,33.9,21.5,15.5,15.2,13.3,19.2,27.3,26,30.4,15.8,19.7,15,21.4],"type":"scatter3d","mode":"markers","opacity":0.8,"marker":{"color":"rgba(31,119,180,1)","line":{"color":"rgba(31,119,180,1)"}},"error_y":{"color":"rgba(31,119,180,1)"},"error_x":{"color":"rgba(31,119,180,1)"},"line":{"color":"rgba(31,119,180,1)"},"frame":null},{"colorbar":{"title":"mpg","ticklen":2,"len":0.5,"lenmode":"fraction","y":1,"yanchor":"top"},"colorscale":[["0","rgba(68,1,84,1)"],["0.0416666666666667","rgba(70,19,97,1)"],["0.0833333333333333","rgba(72,32,111,1)"],["0.125","rgba(71,45,122,1)"],["0.166666666666667","rgba(68,58,128,1)"],["0.208333333333333","rgba(64,70,135,1)"],["0.25","rgba(60,82,138,1)"],["0.291666666666667","rgba(56,93,140,1)"],["0.333333333333333","rgba(49,104,142,1)"],["0.375","rgba(46,114,142,1)"],["0.416666666666667","rgba(42,123,142,1)"],["0.458333333333333","rgba(38,133,141,1)"],["0.5","rgba(37,144,140,1)"],["0.541666666666667","rgba(33,154,138,1)"],["0.583333333333333","rgba(39,164,133,1)"],["0.625","rgba(47,174,127,1)"],["0.666666666666667","rgba(53,183,121,1)"],["0.708333333333333","rgba(79,191,110,1)"],["0.75","rgba(98,199,98,1)"],["0.791666666666667","rgba(119,207,85,1)"],["0.833333333333333","rgba(147,214,70,1)"],["0.875","rgba(172,220,52,1)"],["0.916666666666667","rgba(199,225,42,1)"],["0.958333333333333","rgba(226,228,40,1)"],["1","rgba(253,231,37,1)"]],"showscale":true,"z":[[28.6305259890832,28.3462919899241,28.062057990765,27.777823991606,27.4935899924469,27.2093559932878,26.9251219941288,26.6408879949697,26.3566539958106,26.0724199966515,25.7881859974925,25.5039519983334,25.2197179991743,24.9354840000153,24.6512500008562,24.3670160016971,24.082782002538,23.798548003379,23.5143140042199,23.2300800050608,22.9458460059018,22.6616120067427,22.3773780075836,22.0931440084245,21.8089100092655,21.5246760101064],[28.1063228739342,27.8220888747751,27.537854875616,27.253620876457,26.9693868772979,26.6851528781388,26.4009188789797,26.1166848798207,25.8324508806616,25.5482168815025,25.2639828823435,24.9797488831844,24.6955148840253,24.4112808848662,24.1270468857072,23.8428128865481,23.558578887389,23.27434488823,22.9901108890709,22.7058768899118,22.4216428907527,22.1374088915937,21.8531748924346,21.5689408932755,21.2847068941165,21.0004728949574],[27.5821197587852,27.2978857596261,27.013651760467,26.7294177613079,26.4451837621489,26.1609497629898,25.8767157638307,25.5924817646717,25.3082477655126,25.0240137663535,24.7397797671944,24.4555457680354,24.1713117688763,23.8870777697172,23.6028437705582,23.3186097713991,23.03437577224,22.7501417730809,22.4659077739219,22.1816737747628,21.8974397756037,21.6132057764447,21.3289717772856,21.0447377781265,20.7605037789674,20.4762697798084],[27.0579166436362,26.7736826444771,26.489448645318,26.2052146461589,25.9209806469999,25.6367466478408,25.3525126486817,25.0682786495227,24.7840446503636,24.4998106512045,24.2155766520454,23.9313426528864,23.6471086537273,23.3628746545682,23.0786406554092,22.7944066562501,22.510172657091,22.2259386579319,21.9417046587729,21.6574706596138,21.3732366604547,21.0890026612957,20.8047686621366,20.5205346629775,20.2363006638184,19.9520666646594],[26.5337135284871,26.2494795293281,25.965245530169,25.6810115310099,25.3967775318509,25.1125435326918,24.8283095335327,24.5440755343736,24.2598415352146,23.9756075360555,23.6913735368964,23.4071395377374,23.1229055385783,22.8386715394192,22.5544375402601,22.2702035411011,21.985969541942,21.7017355427829,21.4175015436239,21.1332675444648,20.8490335453057,20.5647995461466,20.2805655469876,19.9963315478285,19.7120975486694,19.4278635495104],[26.0095104133381,25.7252764141791,25.44104241502,25.1568084158609,24.8725744167018,24.5883404175428,24.3041064183837,24.0198724192246,23.7356384200656,23.4514044209065,23.1671704217474,22.8829364225883,22.5987024234293,22.3144684242702,22.0302344251111,21.7460004259521,21.461766426793,21.1775324276339,20.8932984284748,20.6090644293158,20.3248304301567,20.0405964309976,19.7563624318386,19.4721284326795,19.1878944335204,18.9036604343613],[25.4853072981891,25.20107329903,24.916839299871,24.6326053007119,24.3483713015528,24.0641373023938,23.7799033032347,23.4956693040756,23.2114353049165,22.9272013057575,22.6429673065984,22.3587333074393,22.0744993082803,21.7902653091212,21.5060313099621,21.221797310803,20.937563311644,20.6533293124849,20.3690953133258,20.0848613141668,19.8006273150077,19.5163933158486,19.2321593166895,18.9479253175305,18.6636913183714,18.3794573192123],[24.9611041830401,24.676870183881,24.392636184722,24.1084021855629,23.8241681864038,23.5399341872448,23.2557001880857,22.9714661889266,22.6872321897675,22.4029981906085,22.1187641914494,21.8345301922903,21.5502961931313,21.2660621939722,20.9818281948131,20.697594195654,20.413360196495,20.1291261973359,19.8448921981768,19.5606581990178,19.2764241998587,18.9921902006996,18.7079562015405,18.4237222023815,18.1394882032224,17.8552542040633],[24.4369010678911,24.152667068732,23.868433069573,23.5841990704139,23.2999650712548,23.0157310720957,22.7314970729367,22.4472630737776,22.1630290746185,21.8787950754595,21.5945610763004,21.3103270771413,21.0260930779822,20.7418590788232,20.4576250796641,20.173391080505,19.889157081346,19.6049230821869,19.3206890830278,19.0364550838687,18.7522210847097,18.4679870855506,18.1837530863915,17.8995190872325,17.6152850880734,17.3310510889143],[23.9126979527421,23.628463953583,23.344229954424,23.0599959552649,22.7757619561058,22.4915279569467,22.2072939577877,21.9230599586286,21.6388259594695,21.3545919603105,21.0703579611514,20.7861239619923,20.5018899628332,20.2176559636742,19.9334219645151,19.649187965356,19.3649539661969,19.0807199670379,18.7964859678788,18.5122519687197,18.2280179695607,17.9437839704016,17.6595499712425,17.3753159720834,17.0910819729244,16.8068479737653],[23.3884948375931,23.104260838434,22.8200268392749,22.5357928401159,22.2515588409568,21.9673248417977,21.6830908426387,21.3988568434796,21.1146228443205,20.8303888451614,20.5461548460024,20.2619208468433,19.9776868476842,19.6934528485252,19.4092188493661,19.124984850207,18.8407508510479,18.5565168518889,18.2722828527298,17.9880488535707,17.7038148544117,17.4195808552526,17.1353468560935,16.8511128569344,16.5668788577754,16.2826448586163],[22.8642917224441,22.580057723285,22.2958237241259,22.0115897249669,21.7273557258078,21.4431217266487,21.1588877274896,20.8746537283306,20.5904197291715,20.3061857300124,20.0219517308534,19.7377177316943,19.4534837325352,19.1692497333761,18.8850157342171,18.600781735058,18.3165477358989,18.0323137367399,17.7480797375808,17.4638457384217,17.1796117392626,16.8953777401036,16.6111437409445,16.3269097417854,16.0426757426264,15.7584417434673],[22.3400886072951,22.055854608136,21.7716206089769,21.4873866098178,21.2031526106588,20.9189186114997,20.6346846123406,20.3504506131816,20.0662166140225,19.7819826148634,19.4977486157043,19.2135146165453,18.9292806173862,18.6450466182271,18.3608126190681,18.076578619909,17.7923446207499,17.5081106215908,17.2238766224318,16.9396426232727,16.6554086241136,16.3711746249546,16.0869406257955,15.8027066266364,15.5184726274773,15.2342386283183],[21.8158854921461,21.531651492987,21.2474174938279,20.9631834946688,20.6789494955098,20.3947154963507,20.1104814971916,19.8262474980326,19.5420134988735,19.2577794997144,18.9735455005553,18.6893115013963,18.4050775022372,18.1208435030781,17.8366095039191,17.55237550476,17.2681415056009,16.9839075064418,16.6996735072828,16.4154395081237,16.1312055089646,15.8469715098056,15.5627375106465,15.2785035114874,14.9942695123283,14.7100355131693],[21.291682376997,21.007448377838,20.7232143786789,20.4389803795198,20.1547463803608,19.8705123812017,19.5862783820426,19.3020443828835,19.0178103837245,18.7335763845654,18.4493423854063,18.1651083862473,17.8808743870882,17.5966403879291,17.31240638877,17.028172389611,16.7439383904519,16.4597043912928,16.1754703921338,15.8912363929747,15.6070023938156,15.3227683946565,15.0385343954975,14.7543003963384,14.4700663971793,14.1858323980203],[20.767479261848,20.483245262689,20.1990112635299,19.9147772643708,19.6305432652117,19.3463092660527,19.0620752668936,18.7778412677345,18.4936072685755,18.2093732694164,17.9251392702573,17.6409052710982,17.3566712719392,17.0724372727801,16.788203273621,16.503969274462,16.2197352753029,15.9355012761438,15.6512672769847,15.3670332778257,15.0827992786666,14.7985652795075,14.5143312803485,14.2300972811894,13.9458632820303,13.6616292828712],[20.243276146699,19.95904214754,19.6748081483809,19.3905741492218,19.1063401500627,18.8221061509037,18.5378721517446,18.2536381525855,17.9694041534265,17.6851701542674,17.4009361551083,17.1167021559492,16.8324681567902,16.5482341576311,16.264000158472,15.979766159313,15.6955321601539,15.4112981609948,15.1270641618357,14.8428301626767,14.5585961635176,14.2743621643585,13.9901281651995,13.7058941660404,13.4216601668813,13.1374261677222],[19.71907303155,19.4348390323909,19.1506050332319,18.8663710340728,18.5821370349137,18.2979030357547,18.0136690365956,17.7294350374365,17.4452010382774,17.1609670391184,16.8767330399593,16.5924990408002,16.3082650416412,16.0240310424821,15.739797043323,15.4555630441639,15.1713290450049,14.8870950458458,14.6028610466867,14.3186270475277,14.0343930483686,13.7501590492095,13.4659250500504,13.1816910508914,12.8974570517323,12.6132230525732],[19.194869916401,18.9106359172419,18.6264019180829,18.3421679189238,18.0579339197647,17.7736999206056,17.4894659214466,17.2052319222875,16.9209979231284,16.6367639239694,16.3525299248103,16.0682959256512,15.7840619264921,15.4998279273331,15.215593928174,14.9313599290149,14.6471259298559,14.3628919306968,14.0786579315377,13.7944239323786,13.5101899332196,13.2259559340605,12.9417219349014,12.6574879357424,12.3732539365833,12.0890199374242],[18.670666801252,18.3864328020929,18.1021988029338,17.8179648037748,17.5337308046157,17.2494968054566,16.9652628062976,16.6810288071385,16.3967948079794,16.1125608088204,15.8283268096613,15.5440928105022,15.2598588113431,14.9756248121841,14.691390813025,14.4071568138659,14.1229228147069,13.8386888155478,13.5544548163887,13.2702208172296,12.9859868180706,12.7017528189115,12.4175188197524,12.1332848205933,11.8490508214343,11.5648168222752],[18.146463686103,17.8622296869439,17.5779956877848,17.2937616886258,17.0095276894667,16.7252936903076,16.4410596911486,16.1568256919895,15.8725916928304,15.5883576936713,15.3041236945123,15.0198896953532,14.7356556961941,14.4514216970351,14.167187697876,13.8829536987169,13.5987196995578,13.3144857003988,13.0302517012397,12.7460177020806,12.4617837029216,12.1775497037625,11.8933157046034,11.6090817054443,11.3248477062853,11.0406137071262],[17.622260570954,17.3380265717949,17.0537925726358,16.7695585734768,16.4853245743177,16.2010905751586,15.9168565759995,15.6326225768405,15.3483885776814,15.0641545785223,14.7799205793633,14.4956865802042,14.2114525810451,13.927218581886,13.642984582727,13.3587505835679,13.0745165844088,12.7902825852498,12.5060485860907,12.2218145869316,11.9375805877725,11.6533465886135,11.3691125894544,11.0848785902953,10.8006445911363,10.5164105919772],[17.098057455805,16.8138234566459,16.5295894574868,16.2453554583277,15.9611214591687,15.6768874600096,15.3926534608505,15.1084194616915,14.8241854625324,14.5399514633733,14.2557174642142,13.9714834650552,13.6872494658961,13.403015466737,13.118781467578,12.8345474684189,12.5503134692598,12.2660794701007,11.9818454709417,11.6976114717826,11.4133774726235,11.1291434734645,10.8449094743054,10.5606754751463,10.2764414759872,9.99220747682818],[16.573854340656,16.2896203414969,16.0053863423378,15.7211523431787,15.4369183440197,15.1526843448606,14.8684503457015,14.5842163465425,14.2999823473834,14.0157483482243,13.7315143490652,13.4472803499062,13.1630463507471,12.878812351588,12.594578352429,12.3103443532699,12.0261103541108,11.7418763549517,11.4576423557927,11.1734083566336,10.8891743574745,10.6049403583155,10.3207063591564,10.0364723599973,9.75223836083824,9.46800436167917],[16.0496512255069,15.7654172263479,15.4811832271888,15.1969492280297,14.9127152288707,14.6284812297116,14.3442472305525,14.0600132313934,13.7757792322344,13.4915452330753,13.2073112339162,12.9230772347572,12.6388432355981,12.354609236439,12.0703752372799,11.7861412381209,11.5019072389618,11.2176732398027,10.9334392406437,10.6492052414846,10.3649712423255,10.0807372431664,9.79650324400737,9.5122692448483,9.22803524568923,8.94380124653016],[15.5254481103579,15.2412141111989,14.9569801120398,14.6727461128807,14.3885121137216,14.1042781145626,13.8200441154035,13.5358101162444,13.2515761170854,12.9673421179263,12.6831081187672,12.3988741196081,12.1146401204491,11.83040612129,11.5461721221309,11.2619381229719,10.9777041238128,10.6934701246537,10.4092361254947,10.1250021263356,9.84076812717651,9.55653412801743,9.27230012885836,8.98806612969929,8.70383213054022,8.41959813138115]],"x":[1.513,1.66944,1.82588,1.98232,2.13876,2.2952,2.45164,2.60808,2.76452,2.92096,3.0774,3.23384,3.39028,3.54672,3.70316,3.8596,4.01604,4.17248,4.32892,4.48536,4.6418,4.79824,4.95468,5.11112,5.26756,5.424],"y":[71.1,87.136,103.172,119.208,135.244,151.28,167.316,183.352,199.388,215.424,231.46,247.496,263.532,279.568,295.604,311.64,327.676,343.712,359.748,375.784,391.82,407.856,423.892,439.928,455.964,472],"type":"surface","opacity":0.9,"frame":null}],"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> ] --- class: letra ## Regressão Linear Múltipla ### Regressão Linear Simples $$ y = \beta_0 + \beta_1x $$ ### Regressão Linear Múltipla $$ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \dots + \beta_px_p $$ ```r # ajuste de uma regressão linear múltipla no R *modelo_boston <- lm(medv ~ lstat + age, data = Boston) summary(modelo_boston) # Estimate Std.Error t value Pr(>|t|) # (Intercept) 33.22 0.73 45.4 < 2e-16 *** # lstat -1.03 0.04 -21.4 < 2e-16 *** # age 0.03 0.01 2.8 0.00491 ** ``` --- ## Preditores Categóricos ### Preditor com apenas 2 categorias Tamanho das nadadeiras de pinguins são diferentes entre os sexos? <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-47-1.png" style="display: block; margin: auto;" /> ```r summary(lm(flipper_length_mm ~ sex, data = penguins)) # Coefficients: # Estimate Std. Error t value Pr(>|t|) # (Intercept) 197.364 1.057 186.792 < 2e-16 *** # sexmale 7.142 1.488 4.801 2.39e-06 *** ``` --- ## Preditores Categóricos ### Preditor com apenas 2 categorias Tamanho das nadadeiras de pinguins são diferentes entre os sexos? <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-49-1.png" style="display: block; margin: auto;" /> $$ y_i = \beta_0 + \beta_1x_i \space\space\space\space\space\space \text{em que}\space\space\space\space\space\space x_i = \Bigg\\{\begin{array}{ll}1&\text{se a i-ésimo animal for }\texttt{female}\\\\ 0&\text{se a i-ésimo animal for } \texttt{male}\end{array} $$ .letrinha[ ```r # lembrete: exercícios 8, 9 e 10 do script! ``` Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 84 (Predictors with Only Two Levels). ] --- ## Preditores Categóricos ### Preditor com 3 ou mais categorias .pull-left-letrinha[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-51-1.png" style="display: block; margin: auto;" /> ```r summary(lm(flipper_length_mm ~ species, data = penguins)) # Estimate Std. Error t value Pr(>|t|) # (Intercept) 189.9536 0.5405 351.454 < 2e-16 *** # speciesChinstrap 5.8699 0.9699 6.052 3.79e-09 *** # speciesGentoo 27.2333 0.8067 33.760 < 2e-16 *** ``` ] .pull-right[ Modelo `$$y_i = \beta_0 + \beta_1x_{1i} + \beta_2x_{2i}$$` Em que `\(x_{1i} = \Bigg \{ \begin{array}{ll} 1 & \text{se for }\texttt{Chinstrap}\\0&\text{caso contrário}\end{array}\)` `\(x_{2i} = \Bigg \{ \begin{array}{ll} 1 & \text{se for }\texttt{Gentoo}\\0&\text{caso contrário}\end{array}\)` ] --- ## Preditores Categóricos ### Preditor com 3 ou mais categorias "One hot enconding" ou "Dummies" ou "Indicadores". <table> <thead> <tr> <th style="text-align:left;"> species </th> <th style="text-align:right;"> (Intercept) </th> <th style="text-align:right;"> speciesChinstrap </th> <th style="text-align:right;"> speciesGentoo </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Adelie </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Chinstrap </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Gentoo </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> Adelie </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Gentoo </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> Adelie </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Adelie </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Chinstrap </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> --- ## Preditores Categóricos ### Preditor com 3 ou mais categorias Interpretação dos parâmetros: `\(y_{i} = \left\{ \begin{array}{ll} \beta_0 & \text{se for }\texttt{Adelie}\\ \beta_0 + \beta_1&\text{se for } \texttt{Chinstrap}\\ \beta_0 + \beta_2&\text{se for } \texttt{Gentoo}\end{array}\right.\)` ```r # interprete cada um dos três parâmetros individualmente. # lembrete: exercício 11 do script! ``` --- ## Transformações Não Lineares dos Preditores ### Exemplo: log .pull-left[ Modelo real: `\(y = 10 + 0.5log(x)\)` ] .pull-right[ Modelo proposto: `\(\small y = \beta_0 + \beta_1log(x)\)` ] <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-56-1.png" style="display: block; margin: auto;" /> Outras transformações comuns: raíz quadrada, polinômios, Box-Cox, ... .letrinha[ ```r # lembrete: exercício 13 do script! ``` ] --- ## Transformações Não Lineares dos Preditores ### Exemplo: log .pull-left[ Modelo real: `\(y = 10 + 0.5log(x)\)` ] .pull-right[ Modelo proposto: `\(\small y = \beta_0 + \beta_1log(x)\)` ] <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-58-1.png" style="display: block; margin: auto;" /> Outras transformações comuns: raíz quadrada, polinômios, Box-Cox, ... ```r # lembrete: exercício 13 do script! ``` --- ## Transformações Não Lineares dos Preditores ### Gráfico de Resíduos <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-60-1.png" style="display: block; margin: auto;" /> --- ## Transformações Não Lineares dos Preditores ### Exemplo: Regressão Polinomial .pull-left-letrinha[ Modelo real: `\(y = 500 + 0.4(x-10)^3\)` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-61-1.png" style="display: block; margin: auto;" /> ] .pull-right-letrinha[ Modelo proposto: `\(y = \beta_0 + \beta_1x + \beta_2x^2 + \beta_3x^3\)` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-62-1.png" style="display: block; margin: auto;" /> ] .letrinha[ ```r # lembrete: exercício 14 do script! ``` ] --- ## Transformações Não Lineares dos Preditores ### Exemplo: Regressão Polinomial .pull-left-letrinha[ Modelo real: `\(y = 500 + 0.4(x-10)^3\)` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-64-1.png" style="display: block; margin: auto;" /> ] .pull-right-letrinha[ Modelo proposto: `\(y = \beta_0 + \beta_1x + \beta_2x^2 + \beta_3x^3\)` <table class="table" style="font-size: 16px; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:right;"> y </th> <th style="text-align:right;"> x </th> <th style="text-align:right;"> x2 </th> <th style="text-align:right;"> x3 </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 456.5 </td> <td style="text-align:right;"> 5.3 </td> <td style="text-align:right;"> 28.2 </td> <td style="text-align:right;"> 149.7 </td> </tr> <tr> <td style="text-align:right;"> 492.5 </td> <td style="text-align:right;"> 7.4 </td> <td style="text-align:right;"> 55.4 </td> <td style="text-align:right;"> 412.2 </td> </tr> <tr> <td style="text-align:right;"> 548.4 </td> <td style="text-align:right;"> 11.5 </td> <td style="text-align:right;"> 131.3 </td> <td style="text-align:right;"> 1503.9 </td> </tr> <tr> <td style="text-align:right;"> 758.7 </td> <td style="text-align:right;"> 18.2 </td> <td style="text-align:right;"> 329.9 </td> <td style="text-align:right;"> 5993.0 </td> </tr> <tr> <td style="text-align:right;"> 444.7 </td> <td style="text-align:right;"> 4.0 </td> <td style="text-align:right;"> 16.3 </td> <td style="text-align:right;"> 65.6 </td> </tr> <tr> <td style="text-align:right;"> 748.3 </td> <td style="text-align:right;"> 18.0 </td> <td style="text-align:right;"> 322.8 </td> <td style="text-align:right;"> 5800.8 </td> </tr> <tr> <td style="text-align:right;"> 820.5 </td> <td style="text-align:right;"> 18.9 </td> <td style="text-align:right;"> 357.0 </td> <td style="text-align:right;"> 6744.3 </td> </tr> </tbody> </table> ] .letrinha[ ```r # lembrete: exercício 14 do script! ``` ] --- ## Transformações Não Lineares dos Preditores ### Gráfico de Resíduos <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-67-1.png" style="display: block; margin: auto;" /> --- ## Interações Interação entre duas variáveis explicativas: `Species` e `Sepal.Length` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-68-1.png" height="330" style="display: block; margin: auto;" /> --- ## Interações Modelo proposto (Matemático): Seja `y = Sepal.Width` e `x = Sepal.Length`, `$$\small \begin{array}{l} y = \beta_0 + \beta_1x\end{array}$$` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-69-1.png" height="260" style="display: block; margin: auto;" /> Modelo proposto (em R): `Sepal.Width ~ Sepal.Length` ```r # lembrete: exercícios 14 ao 17 do script! ``` --- ## Interações Modelo proposto (Matemático): Seja `y = Sepal.Width` e `x = Sepal.Length`, `$$\small \begin{array}{l} y = \beta_0 + \beta_1x + \beta_2I_{versicolor} + \beta_3I_{virginica}\end{array}$$` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-71-1.png" height="260" style="display: block; margin: auto;" /> Modelo proposto (em R): `Sepal.Width ~ Sepal.Length + Species` ```r # lembrete: exercícios 14 ao 17 do script! ``` --- ## Interações Modelo proposto (Matemático): Seja `y = Sepal.Width` e `x = Sepal.Length`, `$$\small \begin{array}{l} y = \beta_0 + \beta_1x + \beta_2I_{versicolor} + \beta_3I_{virginica} + \beta_4\color{red}{xI_{versicolor}} + \beta_5\color{red}{xI_{virginica}}\end{array}$$` <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-73-1.png" height="260" style="display: block; margin: auto;" /> Modelo proposto (em R): `Sepal.Width ~ Sepal.Length * Species` ```r # lembrete: exercícios 14 ao 17 do script! ``` --- ## Heterocedasticidade <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-75-1.png" style="display: block; margin: auto;" /> --- ## Heterocedasticidade <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-76-1.png" style="display: block; margin: auto;" /> --- ## Heterocedasticidade <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-77-1.png" style="display: block; margin: auto;" /> --- ## Heterocedasticidade ### Problema - O estimador `\(\hat{\sigma}_{\beta_1} = \sqrt{\frac{EQM}{\sum(x_i - \bar{x})^2}}\)` deixa de ter as melhores propriedades. Poderíamos ter conclusões estranhas para `\(\beta_1\)`. ### Diagnóstico - Visualização dos resíduos; - Testes formais (Breuch-Pagan, White, etc) ### Tratamentos - Transformações na variável resposta. log(y), sqrt(y), 1/y, etc; - Mínimos Quadrados Ponderados/Generalizados --- ## Multicolinearidade .pull-left[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-78-1.png" style="display: block; margin: auto;" /> ] .pull-right[ Modelo 1: sem colineares <table class="table" style="font-size: 13px; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:left;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> (Intercept) </td> <td style="text-align:right;"> -173.41 </td> <td style="text-align:left;"> <span style=" color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;text-align: r;">43.83</span> </td> <td style="text-align:right;"> -3.96 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Limit </td> <td style="text-align:right;"> 0.17 </td> <td style="text-align:left;"> <span style=" color: white !important;padding-right: 4px; padding-left: 4px; background-color: darkred !important;text-align: r;">0.01</span> </td> <td style="text-align:right;"> 34.50 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> Age </td> <td style="text-align:right;"> -2.29 </td> <td style="text-align:left;"> <span style=" color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;text-align: r;">0.67</span> </td> <td style="text-align:right;"> -3.41 </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> Modelo 2: com colineares <table class="table" style="font-size: 13px; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:left;"> std.error </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> (Intercept) </td> <td style="text-align:right;"> -377.54 </td> <td style="text-align:left;"> <span style=" color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;text-align: r;">45.25</span> </td> <td style="text-align:right;"> -8.34 </td> <td style="text-align:right;"> 0.00 </td> </tr> <tr> <td style="text-align:left;"> Limit </td> <td style="text-align:right;"> 0.02 </td> <td style="text-align:left;"> <span style=" color: white !important;padding-right: 4px; padding-left: 4px; background-color: darkred !important;text-align: r;">0.06</span> </td> <td style="text-align:right;"> 0.38 </td> <td style="text-align:right;"> 0.70 </td> </tr> <tr> <td style="text-align:left;"> Rating </td> <td style="text-align:right;"> 2.20 </td> <td style="text-align:left;"> <span style=" color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;text-align: r;">0.95</span> </td> <td style="text-align:right;"> 2.31 </td> <td style="text-align:right;"> 0.02 </td> </tr> </tbody> </table> ] Problema: Instabilidade numérica, desvios padrão inflados e interpretação comprometida. Soluções: eliminar uma das variáveis muito correlacionadas ou Consultar o VIF (Variance Inflation Factor) --- ## Multicolinearidade ### VIF (Variance Inflation Factor) Detecta preditores que são combinações lineares de outros preditores. **Procedimento:** Para cada preditor `\(X_j\)`, 1) Ajusta regressão linear com as demais: `lm(X_j ~ X_1 + ... + X_p)`. 2) Calcula-se o R-quadrado dessa regressão e aplica a fórmula abaixo `$$\small VIF(\hat{\beta}_j) = \frac{1}{1 - R^2_{X_j|X_{-j}}}$$` 3) Remova o preditor se VIF maior que 5 (regra de bolso). ```r # lembrete: exercícios 18 do script! ``` .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 101. ] --- class: middle, center, inverse # Regressão Logística --- # Regressão Logística .pull-left[ ### Para `\(Y \in \{0, 1\}\)` (binário) $$ log\left\(\frac{p}{1-p}\right\) = \beta_0 + \beta_1x $$ Ou... $$ p = \frac{1}{1 + e^{-(\beta_0 + \beta_1x)}} $$ ```r ### No R: glm(spam ~ exclamacoes, data=dt_spam, family = "binomial") ``` ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-83-1.png" width="400" style="display: block; margin: auto;" /> .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 131 (Logistic Regression). ] ] --- class: letra # Regressão Logística <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-84-1.png" style="display: block; margin: auto;" /> --- # Regressão Logística <div id="htmlwidget-06484ed42468d86de4a4" style="width:576px;height:432px;" class="plotly html-widget"></div> <script type="application/json" data-for="htmlwidget-06484ed42468d86de4a4">{"x":{"visdat":{"da857f974c9":["function () ","plotlyVisDat"]},"cur_data":"da857f974c9","attrs":{"da857f974c9":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"x":{},"y":{},"z":{},"color":{},"type":"scatter3d","mode":"markers","opacity":0.8,"inherit":true},"da857f974c9.1":{"alpha_stroke":1,"sizes":[10,100],"spans":[1,20],"z":[[0.997197197571356,0.996574361029644,0.995813699282318,0.994884999818742,0.993751568079215,0.992368905911131,0.990683154715481,0.988629278614756,0.986128969953463,0.983088273148812,0.979394946632657,0.97491562072242,0.969492867181979,0.962942380267185,0.95505058545015,0.945573145122201,0.934235019329892,0.920732951893915,0.904741456915993,0.885923517960796,0.863947186143763,0.838508942842767,0.809363932465874,0.776361864471894,0.739485555281711,0.698886992827481],[0.99634439716642,0.995532900925593,0.994542249858377,0.993333377164674,0.991858935192382,0.990061656841293,0.987872450225226,0.985208212468013,0.981969365050815,0.97803714097637,0.973270697887959,0.967504196950361,0.960544081174746,0.952166914855776,0.942118310955005,0.930113671708744,0.915841682158298,0.898971687312411,0.879166180385972,0.856099523844602,0.829483577479179,0.799099978113668,0.764837328151875,0.726729594445378,0.684989954946836,0.640032828652043],[0.995233358024793,0.994176667072368,0.992887398167564,0.991315182410314,0.989399144395613,0.987065906828702,0.98422731278283,0.980777875594604,0.976591998859776,0.971521059248775,0.965390518957753,0.957997338964015,0.949108104181507,0.9384584484788,0.925754573909434,0.910677870993883,0.892893816878735,0.872066373000165,0.847878903662214,0.820062047207214,0.788427863747004,0.752907923350523,0.713590953053653,0.670753692125612,0.624877467760432,0.576643556034668],[0.993786749018682,0.992411812295775,0.990735450872463,0.988692971753892,0.986206473174087,0.983182476265909,0.979509293821797,0.975054192663789,0.969660463421431,0.963144594723813,0.955293864223015,0.945864810914316,0.934583241064377,0.921146632006118,0.905230003593027,0.886496467424972,0.864613644168527,0.839276829107427,0.810239040003203,0.777346791060462,0.740578620733075,0.700081314163373,0.656196967874981,0.609473365081613,0.560651378897069,0.510626661449049],[0.991904685534114,0.990117406713036,0.987940331027964,0.985290783605813,0.982069687127942,0.978158855233692,0.973418109002463,0.967682354111663,0.960758849259057,0.952425023398505,0.94242736346264,0.930482091906796,0.916278567791277,0.899486537595746,0.879768462660963,0.856798051958483,0.830285693065782,0.800010559759469,0.76585770279875,0.727856484498417,0.686214648907743,0.641340790109185,0.59384784903001,0.544532256202645,0.494327560415421,0.444236998882634],[0.989458571110415,0.987138243271998,0.984315272353966,0.980884698043965,0.976721531220355,0.971677838764448,0.965579852025138,0.958225366690772,0.949381840699469,0.93878577268917,0.92614414926892,0.911138962235575,0.893435969003697,0.872698919328768,0.848610280030823,0.820898912668233,0.789374067169186,0.753963408864729,0.71475075689992,0.672007231698772,0.626208336379631,0.578029991745452,0.528319284978978,0.478040507574997,0.42820278611713,0.379780371748244],[0.986283549375306,0.983276163571513,0.979623019646881,0.975192018580769,0.969827167596678,0.963345747747216,0.955535887604295,0.946155002714522,0.934929747408276,0.921558337126858,0.905716305798599,0.887066906075975,0.865277346618829,0.840041760627625,0.81111106791282,0.778328618457756,0.741668702072126,0.70127292318823,0.657477627951011,0.610824847945311,0.562050411148162,0.512046348978192,0.461800012546593,0.412317947864768,0.36454661223409,0.319302879879023],[0.9821694611507,0.978279909951857,0.973564729231327,0.967859566979514,0.960972495807474,0.952681808394576,0.942734866122238,0.930848714298997,0.916713391697786,0.899999056012626,0.880368151424942,0.857493753682652,0.83108480383773,0.800918042409556,0.766874999516704,0.72898046057355,0.687436754135014,0.642646652534457,0.595217492818866,0.545941047183953,0.495747838225464,0.445640191113577,0.396613647116759,0.349579494603408,0.305300866987038,0.264351236054495],[0.976850363781619,0.971833780215191,0.965768186062515,0.958452210169231,0.949654182950244,0.939111468899183,0.92653184270061,0.911597904323981,0.893975702714411,0.873328792423241,0.849338764874406,0.821732732072573,0.790317164345227,0.755015852776757,0.71590773394762,0.673258323529457,0.62753729770717,0.579415198676639,0.529734915467672,0.479458359521764,0.429594480635006,0.381119585692433,0.334903017949546,0.291649789057711,0.251867319633947,0.21585773359826],[0.969992984141796,0.963545844451529,0.955776661410012,0.946443727019846,0.935274545454211,0.921968074768234,0.906200371169245,0.88763484123541,0.86593829990316,0.840803742149582,0.811980018421758,0.779307345496192,0.742755793979757,0.702461809963318,0.658755998374814,0.61217462990618,0.563448457291218,0.513465842184573,0.463212443052727,0.413695367513637,0.365863795861761,0.320539049442952,0.278364517796844,0.239780792274127,0.205025659942645,0.174154092225248],[0.961185026160777,0.95293727588552,0.943040825636926,0.931213546138307,0.917146161469061,0.900509250153221,0.880965253776968,0.858186634975665,0.831880913822221,0.801822427284683,0.767889215865915,0.730101515887568,0.688656259165053,0.643950399950035,0.596585655472606,0.547349102908038,0.497168184663099,0.447044250375148,0.397974131357215,0.350872459380845,0.30650723740539,0.26545762774972,0.228097432319399,0.194602257471101,0.164974480481325,0.139078536345634],[0.94992513719695,0.939435544006557,0.926917661595831,0.912054704894054,0.894513025503342,0.873955999091829,0.85006436361816,0.822563508635761,0.791257155398778,0.756065251301493,0.717061875912791,0.674506954645912,0.628864334436135,0.580799156132857,0.531150067713564,0.480876542463878,0.430987289010235,0.382460609971434,0.33616975596653,0.29282495528472,0.25293942716202,0.21682098436632,0.184585732902065,0.156187214920186,0.13145346194078,0.110125355206927],[0.935617642279915,0.922375852433924,0.906682207343288,0.88820028024122,0.866596510465412,0.841562778477846,0.812845893840351,0.780282971115313,0.743839891262233,0.703647964682934,0.660032064703022,0.613522692428129,0.564845495827143,0.514885118201464,0.464625464118839,0.415074138670389,0.367182988714728,0.321777742465865,0.279507275571357,0.240818012542557,0.205953269018532,0.174972769387287,0.147785161211049,0.124186134552889,0.103896093550481,0.0865933556268597],[0.917576884690779,0.901017127613706,0.881559776838128,0.85887670183854,0.832674027112767,0.802723715696939,0.768900349520451,0.731219643786506,0.689873152666747,0.645252016497974,0.597952317345445,0.548756401241419,0.498588576806544,0.44844915478797,0.399336193793282,0.352167617053457,0.307716263213678,0.266566972112384,0.22909934418548,0.195494304406647,0.165758666656422,0.139760231702461,0.117266332343716,0.0979803944399665,0.0815731672498703,0.0677071698623643],[0.89504794487365,0.874580546170969,0.850787081737179,0.823391245647763,0.792194040552615,0.757111600773721,0.718213174643311,0.675753112206633,0.630189429371739,0.582181843496346,0.532564719129271,0.482295033619064,0.432381190072958,0.383803426569779,0.337438854410201,0.294002891343823,0.254014548785775,0.217787339729241,0.185442436556447,0.1569374821376,0.132103517781506,0.110683381212716,0.0923668077486315,0.0768195434615386,0.0637055300070288,0.0527024315133289],[0.867251984784279,0.842318874474602,0.813708696561527,0.781255494361174,0.744920988850796,0.704831377674386,0.661305812618528,0.614869017077699,0.566241505320322,0.516304154176146,0.46603905329422,0.416454241038295,0.368504174052583,0.323018946628122,0.280652900150187,0.241858292103534,0.206883982744849,0.175794475835935,0.148502170997297,0.124805416527309,0.104426258825134,0.0870438042029807,0.0723211206627022,0.0599251937829756,0.0495404803482601,0.0408771294572566],[0.833464147868495,0.803621909049061,0.769908398267708,0.732334837745362,0.691087423441586,0.646551486440798,0.599317458883074,0.550162920098855,0.500008991731062,0.449854882419024,0.400699815150019,0.353464952247026,0.308927933610063,0.26767926300091,0.230104345021874,0.19638944334828,0.166545836908741,0.140444723315679,0.117855750701539,0.0984836904414585,0.0819998457774945,0.0680666957785229,0.0563556833435774,0.0465589107036522,0.0383958962822155,0.0316166160964374],[0.793127820127977,0.758154897647632,0.719361622118734,0.676996783500639,0.63151256543207,0.583563240228137,0.533978847159558,0.483713810185193,0.433776162584785,0.385148017365877,0.338710299343082,0.29518358795937,0.255092679807385,0.218756799047531,0.18630220791031,0.157690679855315,0.132756296889281,0.111243881358567,0.0928442364317717,0.0772234482302767,0.0640452668812178,0.0529868104256656,0.0437485257645035,0.0360596110266991,0.0296800995815401,0.0244006542286796],[0.745999081801267,0.706012039397944,0.662577227930908,0.616213585524953,0.567636464399903,0.517722927271374,0.467453188091758,0.4178356542384,0.369827335019897,0.324262649478853,0.281801383774014,0.242901627647076,0.207817801636523,0.176619215079313,0.1492220503819,0.12542734442336,0.104958812577025,0.0874963715039934,0.07270323611459,0.0602460676198067,0.0498086946761207,0.041100468271249,0.0338604766510464,0.0278587823706655,0.022895665347392,0.0187996421145299],[0.692299060423759,0.647848794162076,0.600681060623685,0.551568637444712,0.501429406510447,0.451261411282986,0.402064976057957,0.354764449465186,0.310142237659843,0.268794494145684,0.231112432839507,0.197287675876818,0.167335995525721,0.141132017309413,0.118447734134845,0.098989288010584,0.0824285557968979,0.0684279906595021,0.0566585959341657,0.0468117777216465,0.0386062241526186,0.0317910356593159,0.0261462185443107,0.02148145760981,0.0176338695156192,0.0144652432879473],[0.632833725648825,0.58494332586921,0.535392429282764,0.485132849341743,0.435172185240052,0.386494364132873,0.339984076700224,0.296367035722862,0.256173815405269,0.219729361577061,0.18716504951862,0.158446813048033,0.133411805810207,0.111806863028425,0.0933238791276337,0.0776292980882331,0.0643866909545033,0.0532726375339649,0.0439868334259793,0.0362576235699811,0.0298441651933272,0.02453627409235,0.0201528002935516,0.0165391683727382,0.0135645326292811,0.0111188484257278],[0.569030351761062,0.519141414666852,0.468867845989358,0.419218357810664,0.371152454646924,0.325508838436187,0.282952718552217,0.243948015744786,0.208754726111353,0.177446990553223,0.149944804937154,0.126051925131859,0.1054937623293,0.0879510651571516,0.0730872114469639,0.0605685489000287,0.0500782846178478,0.0413249747571475,0.0340468397157017,0.0280130707666628,0.0230231178197657,0.0189047345532664,0.0155113526388679,0.0127191829075117,0.0104243045105458,0.00853990156392484],[0.502849798218504,0.452668719343586,0.403431657054112,0.356066093089969,0.311359164295527,0.269912659148734,0.232123605537112,0.198189003483813,0.168129146730584,0.141822119767198,0.119042289806977,0.0994971947543059,0.0828593048819309,0.0687910617184841,0.056963038400432,0.0470659502961777,0.0388176576630112,0.0319663856805951,0.0262912788723795,0.0216012117016279,0.0177325629082968,0.0145464650865867,0.0119258789549021,0.00977271683975849,0.00800514864528494,0.00655515999200087],[0.436569236667077,0.387842448539514,0.341260172289594,0.297553225092888,0.257257950633671,0.220705026468437,0.188030963855155,0.159205886634175,0.134070051056758,0.112372333591301,0.0938057434770677,0.078037100521679,0.0647298092746322,0.0535599192800632,0.0442263791633208,0.0364566823271433,0.0300091096783768,0.0246726286740295,0.0202653008315894,0.0166318386622868,0.0136407669715031,0.0111814935253796,0.00916148062460032,0.00750362754520152,0.00614391778936467,0.00502934840033476],[0.372479515850318,0.326757500787486,0.284106896462683,0.244997452849348,0.209694756489334,0.178277805620433,0.15067044018677,0.126679165516533,0.106031115595259,0.0884078927925857,0.0734730540289337,0.0608926444886151,0.0503492563985588,0.041550654444092,0.0342341921499694,0.0281681888885206,0.0231512629668489,0.0190104030901513,0.015598355334859,0.0127907278842805,0.0104830779387547,0.00858814271724541,0.00703330387924214,0.00575832558988529,0.00471337482056773,0.0038573133062526],[0.312578702316924,0.271033751483425,0.233137860900655,0.19909342757086,0.16892529468163,0.14251503673136,0.119639424860267,0.100007418274347,0.0832921006125248,0.0691559161821281,0.0572690174105567,0.047321434429949,0.0390302021148005,0.0321426707726361,0.0264371221534362,0.0217216185747189,0.0178317986424822,0.0146281361733928,0.0119930158295626,0.00982785302688467,0.00805039355424113,0.0065922640612815,0.00539680174308447,0.00441716445054302,0.00361470643057517,0.0029575963866333]],"x":[0.0144823438022286,0.0525416156277061,0.0906008874531835,0.128660159278661,0.166719431104139,0.204778702929616,0.242837974755093,0.280897246580571,0.318956518406048,0.357015790231526,0.395075062057003,0.433134333882481,0.471193605707958,0.509252877533436,0.547312149358913,0.585371421184391,0.623430693009868,0.661489964835346,0.699549236660823,0.737608508486301,0.775667780311778,0.813727052137256,0.851786323962733,0.889845595788211,0.927904867613688,0.965964139439166],"y":[0.0227246168069541,0.0613890595827252,0.100053502358496,0.138717945134267,0.177382387910038,0.216046830685809,0.25471127346158,0.293375716237351,0.332040159013122,0.370704601788893,0.409369044564664,0.448033487340435,0.486697930116206,0.525362372891977,0.564026815667748,0.60269125844352,0.641355701219291,0.680020143995061,0.718684586770833,0.757349029546604,0.796013472322375,0.834677915098146,0.873342357873917,0.912006800649688,0.950671243425459,0.98933568620123],"type":"surface","opacity":0.9,"inherit":true}},"layout":{"margin":{"b":40,"l":60,"t":25,"r":10},"scene":{"xaxis":{"title":"tempo_de_relacionamento"},"yaxis":{"title":"idade"},"zaxis":{"title":"churn"}},"hovermode":"closest","showlegend":false,"legend":{"yanchor":"top","y":0.5}},"source":"A","config":{"modeBarButtonsToAdd":["hoverclosest","hovercompare"],"showSendToCloud":false},"data":[{"x":[0.200214452575892,0.685218595666811,0.91687577450648,0.284399457275867,0.104650127934292,0.701057459227741,0.527959984261543,0.807935200864449,0.9565001251176,0.110453018685803,0.273284949595109,0.490513201802969,0.318404018646106,0.559172826586291,0.262593138730153,0.201875211205333,0.387525747064501,0.887869771569967,0.55492255394347,0.842179385246709,0.890207114629447,0.720700970385224,0.211340273730457,0.225717290770262,0.139983697095886,0.479913854040205,0.437411859631538,0.965964139439166,0.141913911094889,0.954978888388723,0.444730556104332,0.0593624736648053,0.275149184744805,0.0311482592951506,0.0144823438022286,0.487169028958306,0.595151623012498,0.597853036830202,0.397680514957756,0.396830396959558],"y":[0.816076069371775,0.235198754351586,0.826870246091858,0.533475931501016,0.928942713653669,0.549794725608081,0.760142526822165,0.0685097624082118,0.793609339045361,0.63280342775397,0.384576936485246,0.566272675059736,0.921990567352623,0.9758776135277,0.933033839333802,0.381162660429254,0.25556407077238,0.257483700523153,0.196886381134391,0.136400904972106,0.623966502491385,0.173745283158496,0.866434578550979,0.98933568620123,0.986635761801153,0.892013083212078,0.888217610539868,0.157343514729291,0.930459470953792,0.826930246781558,0.829343417659402,0.717340295435861,0.156359620392323,0.835461407201365,0.0227246168069541,0.919127090135589,0.0390189492609352,0.700119586894289,0.443299840670079,0.313868451630697],"z":[1,0,0,1,0,0,1,0,0,1,1,0,0,0,0,1,1,0,1,1,1,0,0,1,1,0,0,0,0,0,0,1,1,1,1,0,1,0,1,1],"type":"scatter3d","mode":"markers","opacity":0.8,"marker":{"colorbar":{"title":"tempo_de_relacionamentoidade","ticklen":2},"cmin":0,"cmax":1,"colorscale":[["0","rgba(68,1,84,1)"],["0.0416666666666667","rgba(70,19,97,1)"],["0.0833333333333333","rgba(72,32,111,1)"],["0.125","rgba(71,45,122,1)"],["0.166666666666667","rgba(68,58,128,1)"],["0.208333333333333","rgba(64,70,135,1)"],["0.25","rgba(60,82,138,1)"],["0.291666666666667","rgba(56,93,140,1)"],["0.333333333333333","rgba(49,104,142,1)"],["0.375","rgba(46,114,142,1)"],["0.416666666666667","rgba(42,123,142,1)"],["0.458333333333333","rgba(38,133,141,1)"],["0.5","rgba(37,144,140,1)"],["0.541666666666667","rgba(33,154,138,1)"],["0.583333333333333","rgba(39,164,133,1)"],["0.625","rgba(47,174,127,1)"],["0.666666666666667","rgba(53,183,121,1)"],["0.708333333333333","rgba(79,191,110,1)"],["0.75","rgba(98,199,98,1)"],["0.791666666666667","rgba(119,207,85,1)"],["0.833333333333333","rgba(147,214,70,1)"],["0.875","rgba(172,220,52,1)"],["0.916666666666667","rgba(199,225,42,1)"],["0.958333333333333","rgba(226,228,40,1)"],["1","rgba(253,231,37,1)"]],"showscale":false,"color":[0,1,0,1,0,0,0,1,0,1,1,0,0,0,0,1,1,0,1,1,0,1,0,0,0,0,0,0,0,0,0,1,1,1,1,0,1,0,1,1],"line":{"colorbar":{"title":"","ticklen":2},"cmin":0,"cmax":1,"colorscale":[["0","rgba(68,1,84,1)"],["0.0416666666666667","rgba(70,19,97,1)"],["0.0833333333333333","rgba(72,32,111,1)"],["0.125","rgba(71,45,122,1)"],["0.166666666666667","rgba(68,58,128,1)"],["0.208333333333333","rgba(64,70,135,1)"],["0.25","rgba(60,82,138,1)"],["0.291666666666667","rgba(56,93,140,1)"],["0.333333333333333","rgba(49,104,142,1)"],["0.375","rgba(46,114,142,1)"],["0.416666666666667","rgba(42,123,142,1)"],["0.458333333333333","rgba(38,133,141,1)"],["0.5","rgba(37,144,140,1)"],["0.541666666666667","rgba(33,154,138,1)"],["0.583333333333333","rgba(39,164,133,1)"],["0.625","rgba(47,174,127,1)"],["0.666666666666667","rgba(53,183,121,1)"],["0.708333333333333","rgba(79,191,110,1)"],["0.75","rgba(98,199,98,1)"],["0.791666666666667","rgba(119,207,85,1)"],["0.833333333333333","rgba(147,214,70,1)"],["0.875","rgba(172,220,52,1)"],["0.916666666666667","rgba(199,225,42,1)"],["0.958333333333333","rgba(226,228,40,1)"],["1","rgba(253,231,37,1)"]],"showscale":false,"color":[0,1,0,1,0,0,0,1,0,1,1,0,0,0,0,1,1,0,1,1,0,1,0,0,0,0,0,0,0,0,0,1,1,1,1,0,1,0,1,1]}},"frame":null},{"colorbar":{"title":"tempo_de_relacionamentoidade","ticklen":2,"len":0.5,"lenmode":"fraction","y":1,"yanchor":"top"},"colorscale":[["0","rgba(68,1,84,1)"],["0.0416666666666667","rgba(70,19,97,1)"],["0.0833333333333333","rgba(72,32,111,1)"],["0.125","rgba(71,45,122,1)"],["0.166666666666667","rgba(68,58,128,1)"],["0.208333333333333","rgba(64,70,135,1)"],["0.25","rgba(60,82,138,1)"],["0.291666666666667","rgba(56,93,140,1)"],["0.333333333333333","rgba(49,104,142,1)"],["0.375","rgba(46,114,142,1)"],["0.416666666666667","rgba(42,123,142,1)"],["0.458333333333333","rgba(38,133,141,1)"],["0.5","rgba(37,144,140,1)"],["0.541666666666667","rgba(33,154,138,1)"],["0.583333333333333","rgba(39,164,133,1)"],["0.625","rgba(47,174,127,1)"],["0.666666666666667","rgba(53,183,121,1)"],["0.708333333333333","rgba(79,191,110,1)"],["0.75","rgba(98,199,98,1)"],["0.791666666666667","rgba(119,207,85,1)"],["0.833333333333333","rgba(147,214,70,1)"],["0.875","rgba(172,220,52,1)"],["0.916666666666667","rgba(199,225,42,1)"],["0.958333333333333","rgba(226,228,40,1)"],["1","rgba(253,231,37,1)"]],"showscale":true,"z":[[0.997197197571356,0.996574361029644,0.995813699282318,0.994884999818742,0.993751568079215,0.992368905911131,0.990683154715481,0.988629278614756,0.986128969953463,0.983088273148812,0.979394946632657,0.97491562072242,0.969492867181979,0.962942380267185,0.95505058545015,0.945573145122201,0.934235019329892,0.920732951893915,0.904741456915993,0.885923517960796,0.863947186143763,0.838508942842767,0.809363932465874,0.776361864471894,0.739485555281711,0.698886992827481],[0.99634439716642,0.995532900925593,0.994542249858377,0.993333377164674,0.991858935192382,0.990061656841293,0.987872450225226,0.985208212468013,0.981969365050815,0.97803714097637,0.973270697887959,0.967504196950361,0.960544081174746,0.952166914855776,0.942118310955005,0.930113671708744,0.915841682158298,0.898971687312411,0.879166180385972,0.856099523844602,0.829483577479179,0.799099978113668,0.764837328151875,0.726729594445378,0.684989954946836,0.640032828652043],[0.995233358024793,0.994176667072368,0.992887398167564,0.991315182410314,0.989399144395613,0.987065906828702,0.98422731278283,0.980777875594604,0.976591998859776,0.971521059248775,0.965390518957753,0.957997338964015,0.949108104181507,0.9384584484788,0.925754573909434,0.910677870993883,0.892893816878735,0.872066373000165,0.847878903662214,0.820062047207214,0.788427863747004,0.752907923350523,0.713590953053653,0.670753692125612,0.624877467760432,0.576643556034668],[0.993786749018682,0.992411812295775,0.990735450872463,0.988692971753892,0.986206473174087,0.983182476265909,0.979509293821797,0.975054192663789,0.969660463421431,0.963144594723813,0.955293864223015,0.945864810914316,0.934583241064377,0.921146632006118,0.905230003593027,0.886496467424972,0.864613644168527,0.839276829107427,0.810239040003203,0.777346791060462,0.740578620733075,0.700081314163373,0.656196967874981,0.609473365081613,0.560651378897069,0.510626661449049],[0.991904685534114,0.990117406713036,0.987940331027964,0.985290783605813,0.982069687127942,0.978158855233692,0.973418109002463,0.967682354111663,0.960758849259057,0.952425023398505,0.94242736346264,0.930482091906796,0.916278567791277,0.899486537595746,0.879768462660963,0.856798051958483,0.830285693065782,0.800010559759469,0.76585770279875,0.727856484498417,0.686214648907743,0.641340790109185,0.59384784903001,0.544532256202645,0.494327560415421,0.444236998882634],[0.989458571110415,0.987138243271998,0.984315272353966,0.980884698043965,0.976721531220355,0.971677838764448,0.965579852025138,0.958225366690772,0.949381840699469,0.93878577268917,0.92614414926892,0.911138962235575,0.893435969003697,0.872698919328768,0.848610280030823,0.820898912668233,0.789374067169186,0.753963408864729,0.71475075689992,0.672007231698772,0.626208336379631,0.578029991745452,0.528319284978978,0.478040507574997,0.42820278611713,0.379780371748244],[0.986283549375306,0.983276163571513,0.979623019646881,0.975192018580769,0.969827167596678,0.963345747747216,0.955535887604295,0.946155002714522,0.934929747408276,0.921558337126858,0.905716305798599,0.887066906075975,0.865277346618829,0.840041760627625,0.81111106791282,0.778328618457756,0.741668702072126,0.70127292318823,0.657477627951011,0.610824847945311,0.562050411148162,0.512046348978192,0.461800012546593,0.412317947864768,0.36454661223409,0.319302879879023],[0.9821694611507,0.978279909951857,0.973564729231327,0.967859566979514,0.960972495807474,0.952681808394576,0.942734866122238,0.930848714298997,0.916713391697786,0.899999056012626,0.880368151424942,0.857493753682652,0.83108480383773,0.800918042409556,0.766874999516704,0.72898046057355,0.687436754135014,0.642646652534457,0.595217492818866,0.545941047183953,0.495747838225464,0.445640191113577,0.396613647116759,0.349579494603408,0.305300866987038,0.264351236054495],[0.976850363781619,0.971833780215191,0.965768186062515,0.958452210169231,0.949654182950244,0.939111468899183,0.92653184270061,0.911597904323981,0.893975702714411,0.873328792423241,0.849338764874406,0.821732732072573,0.790317164345227,0.755015852776757,0.71590773394762,0.673258323529457,0.62753729770717,0.579415198676639,0.529734915467672,0.479458359521764,0.429594480635006,0.381119585692433,0.334903017949546,0.291649789057711,0.251867319633947,0.21585773359826],[0.969992984141796,0.963545844451529,0.955776661410012,0.946443727019846,0.935274545454211,0.921968074768234,0.906200371169245,0.88763484123541,0.86593829990316,0.840803742149582,0.811980018421758,0.779307345496192,0.742755793979757,0.702461809963318,0.658755998374814,0.61217462990618,0.563448457291218,0.513465842184573,0.463212443052727,0.413695367513637,0.365863795861761,0.320539049442952,0.278364517796844,0.239780792274127,0.205025659942645,0.174154092225248],[0.961185026160777,0.95293727588552,0.943040825636926,0.931213546138307,0.917146161469061,0.900509250153221,0.880965253776968,0.858186634975665,0.831880913822221,0.801822427284683,0.767889215865915,0.730101515887568,0.688656259165053,0.643950399950035,0.596585655472606,0.547349102908038,0.497168184663099,0.447044250375148,0.397974131357215,0.350872459380845,0.30650723740539,0.26545762774972,0.228097432319399,0.194602257471101,0.164974480481325,0.139078536345634],[0.94992513719695,0.939435544006557,0.926917661595831,0.912054704894054,0.894513025503342,0.873955999091829,0.85006436361816,0.822563508635761,0.791257155398778,0.756065251301493,0.717061875912791,0.674506954645912,0.628864334436135,0.580799156132857,0.531150067713564,0.480876542463878,0.430987289010235,0.382460609971434,0.33616975596653,0.29282495528472,0.25293942716202,0.21682098436632,0.184585732902065,0.156187214920186,0.13145346194078,0.110125355206927],[0.935617642279915,0.922375852433924,0.906682207343288,0.88820028024122,0.866596510465412,0.841562778477846,0.812845893840351,0.780282971115313,0.743839891262233,0.703647964682934,0.660032064703022,0.613522692428129,0.564845495827143,0.514885118201464,0.464625464118839,0.415074138670389,0.367182988714728,0.321777742465865,0.279507275571357,0.240818012542557,0.205953269018532,0.174972769387287,0.147785161211049,0.124186134552889,0.103896093550481,0.0865933556268597],[0.917576884690779,0.901017127613706,0.881559776838128,0.85887670183854,0.832674027112767,0.802723715696939,0.768900349520451,0.731219643786506,0.689873152666747,0.645252016497974,0.597952317345445,0.548756401241419,0.498588576806544,0.44844915478797,0.399336193793282,0.352167617053457,0.307716263213678,0.266566972112384,0.22909934418548,0.195494304406647,0.165758666656422,0.139760231702461,0.117266332343716,0.0979803944399665,0.0815731672498703,0.0677071698623643],[0.89504794487365,0.874580546170969,0.850787081737179,0.823391245647763,0.792194040552615,0.757111600773721,0.718213174643311,0.675753112206633,0.630189429371739,0.582181843496346,0.532564719129271,0.482295033619064,0.432381190072958,0.383803426569779,0.337438854410201,0.294002891343823,0.254014548785775,0.217787339729241,0.185442436556447,0.1569374821376,0.132103517781506,0.110683381212716,0.0923668077486315,0.0768195434615386,0.0637055300070288,0.0527024315133289],[0.867251984784279,0.842318874474602,0.813708696561527,0.781255494361174,0.744920988850796,0.704831377674386,0.661305812618528,0.614869017077699,0.566241505320322,0.516304154176146,0.46603905329422,0.416454241038295,0.368504174052583,0.323018946628122,0.280652900150187,0.241858292103534,0.206883982744849,0.175794475835935,0.148502170997297,0.124805416527309,0.104426258825134,0.0870438042029807,0.0723211206627022,0.0599251937829756,0.0495404803482601,0.0408771294572566],[0.833464147868495,0.803621909049061,0.769908398267708,0.732334837745362,0.691087423441586,0.646551486440798,0.599317458883074,0.550162920098855,0.500008991731062,0.449854882419024,0.400699815150019,0.353464952247026,0.308927933610063,0.26767926300091,0.230104345021874,0.19638944334828,0.166545836908741,0.140444723315679,0.117855750701539,0.0984836904414585,0.0819998457774945,0.0680666957785229,0.0563556833435774,0.0465589107036522,0.0383958962822155,0.0316166160964374],[0.793127820127977,0.758154897647632,0.719361622118734,0.676996783500639,0.63151256543207,0.583563240228137,0.533978847159558,0.483713810185193,0.433776162584785,0.385148017365877,0.338710299343082,0.29518358795937,0.255092679807385,0.218756799047531,0.18630220791031,0.157690679855315,0.132756296889281,0.111243881358567,0.0928442364317717,0.0772234482302767,0.0640452668812178,0.0529868104256656,0.0437485257645035,0.0360596110266991,0.0296800995815401,0.0244006542286796],[0.745999081801267,0.706012039397944,0.662577227930908,0.616213585524953,0.567636464399903,0.517722927271374,0.467453188091758,0.4178356542384,0.369827335019897,0.324262649478853,0.281801383774014,0.242901627647076,0.207817801636523,0.176619215079313,0.1492220503819,0.12542734442336,0.104958812577025,0.0874963715039934,0.07270323611459,0.0602460676198067,0.0498086946761207,0.041100468271249,0.0338604766510464,0.0278587823706655,0.022895665347392,0.0187996421145299],[0.692299060423759,0.647848794162076,0.600681060623685,0.551568637444712,0.501429406510447,0.451261411282986,0.402064976057957,0.354764449465186,0.310142237659843,0.268794494145684,0.231112432839507,0.197287675876818,0.167335995525721,0.141132017309413,0.118447734134845,0.098989288010584,0.0824285557968979,0.0684279906595021,0.0566585959341657,0.0468117777216465,0.0386062241526186,0.0317910356593159,0.0261462185443107,0.02148145760981,0.0176338695156192,0.0144652432879473],[0.632833725648825,0.58494332586921,0.535392429282764,0.485132849341743,0.435172185240052,0.386494364132873,0.339984076700224,0.296367035722862,0.256173815405269,0.219729361577061,0.18716504951862,0.158446813048033,0.133411805810207,0.111806863028425,0.0933238791276337,0.0776292980882331,0.0643866909545033,0.0532726375339649,0.0439868334259793,0.0362576235699811,0.0298441651933272,0.02453627409235,0.0201528002935516,0.0165391683727382,0.0135645326292811,0.0111188484257278],[0.569030351761062,0.519141414666852,0.468867845989358,0.419218357810664,0.371152454646924,0.325508838436187,0.282952718552217,0.243948015744786,0.208754726111353,0.177446990553223,0.149944804937154,0.126051925131859,0.1054937623293,0.0879510651571516,0.0730872114469639,0.0605685489000287,0.0500782846178478,0.0413249747571475,0.0340468397157017,0.0280130707666628,0.0230231178197657,0.0189047345532664,0.0155113526388679,0.0127191829075117,0.0104243045105458,0.00853990156392484],[0.502849798218504,0.452668719343586,0.403431657054112,0.356066093089969,0.311359164295527,0.269912659148734,0.232123605537112,0.198189003483813,0.168129146730584,0.141822119767198,0.119042289806977,0.0994971947543059,0.0828593048819309,0.0687910617184841,0.056963038400432,0.0470659502961777,0.0388176576630112,0.0319663856805951,0.0262912788723795,0.0216012117016279,0.0177325629082968,0.0145464650865867,0.0119258789549021,0.00977271683975849,0.00800514864528494,0.00655515999200087],[0.436569236667077,0.387842448539514,0.341260172289594,0.297553225092888,0.257257950633671,0.220705026468437,0.188030963855155,0.159205886634175,0.134070051056758,0.112372333591301,0.0938057434770677,0.078037100521679,0.0647298092746322,0.0535599192800632,0.0442263791633208,0.0364566823271433,0.0300091096783768,0.0246726286740295,0.0202653008315894,0.0166318386622868,0.0136407669715031,0.0111814935253796,0.00916148062460032,0.00750362754520152,0.00614391778936467,0.00502934840033476],[0.372479515850318,0.326757500787486,0.284106896462683,0.244997452849348,0.209694756489334,0.178277805620433,0.15067044018677,0.126679165516533,0.106031115595259,0.0884078927925857,0.0734730540289337,0.0608926444886151,0.0503492563985588,0.041550654444092,0.0342341921499694,0.0281681888885206,0.0231512629668489,0.0190104030901513,0.015598355334859,0.0127907278842805,0.0104830779387547,0.00858814271724541,0.00703330387924214,0.00575832558988529,0.00471337482056773,0.0038573133062526],[0.312578702316924,0.271033751483425,0.233137860900655,0.19909342757086,0.16892529468163,0.14251503673136,0.119639424860267,0.100007418274347,0.0832921006125248,0.0691559161821281,0.0572690174105567,0.047321434429949,0.0390302021148005,0.0321426707726361,0.0264371221534362,0.0217216185747189,0.0178317986424822,0.0146281361733928,0.0119930158295626,0.00982785302688467,0.00805039355424113,0.0065922640612815,0.00539680174308447,0.00441716445054302,0.00361470643057517,0.0029575963866333]],"x":[0.0144823438022286,0.0525416156277061,0.0906008874531835,0.128660159278661,0.166719431104139,0.204778702929616,0.242837974755093,0.280897246580571,0.318956518406048,0.357015790231526,0.395075062057003,0.433134333882481,0.471193605707958,0.509252877533436,0.547312149358913,0.585371421184391,0.623430693009868,0.661489964835346,0.699549236660823,0.737608508486301,0.775667780311778,0.813727052137256,0.851786323962733,0.889845595788211,0.927904867613688,0.965964139439166],"y":[0.0227246168069541,0.0613890595827252,0.100053502358496,0.138717945134267,0.177382387910038,0.216046830685809,0.25471127346158,0.293375716237351,0.332040159013122,0.370704601788893,0.409369044564664,0.448033487340435,0.486697930116206,0.525362372891977,0.564026815667748,0.60269125844352,0.641355701219291,0.680020143995061,0.718684586770833,0.757349029546604,0.796013472322375,0.834677915098146,0.873342357873917,0.912006800649688,0.950671243425459,0.98933568620123],"type":"surface","opacity":0.9,"marker":{"line":{"colorbar":{"title":"","ticklen":2},"cmin":0,"cmax":1,"colorscale":[["0","rgba(68,1,84,1)"],["0.0416666666666667","rgba(70,19,97,1)"],["0.0833333333333333","rgba(72,32,111,1)"],["0.125","rgba(71,45,122,1)"],["0.166666666666667","rgba(68,58,128,1)"],["0.208333333333333","rgba(64,70,135,1)"],["0.25","rgba(60,82,138,1)"],["0.291666666666667","rgba(56,93,140,1)"],["0.333333333333333","rgba(49,104,142,1)"],["0.375","rgba(46,114,142,1)"],["0.416666666666667","rgba(42,123,142,1)"],["0.458333333333333","rgba(38,133,141,1)"],["0.5","rgba(37,144,140,1)"],["0.541666666666667","rgba(33,154,138,1)"],["0.583333333333333","rgba(39,164,133,1)"],["0.625","rgba(47,174,127,1)"],["0.666666666666667","rgba(53,183,121,1)"],["0.708333333333333","rgba(79,191,110,1)"],["0.75","rgba(98,199,98,1)"],["0.791666666666667","rgba(119,207,85,1)"],["0.833333333333333","rgba(147,214,70,1)"],["0.875","rgba(172,220,52,1)"],["0.916666666666667","rgba(199,225,42,1)"],["0.958333333333333","rgba(226,228,40,1)"],["1","rgba(253,231,37,1)"]],"showscale":false,"color":[0,1,0,1,0,0,0,1,0,1,1,0,0,0,0,1,1,0,1,1,0,1,0,0,0,0,0,0,0,0,0,1,1,1,1,0,1,0,1,1]}},"frame":null}],"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> --- # Regressão Logística - Custo A **Métrica** que a regressão logística usa de **Função de Custo** chama-se *deviance* (ou *log-loss* ou *Binary Cross-Entropy*): `$$D = \frac{-1}{N}\sum[y_i \log\hat{y_i} + (1 - y_i )\log(1 - \hat{y_i})]$$` Para cada linha da base de dados seria assim... .pull-left[ `$$D_i = \begin{cases} \\ -\log(\hat{y}_i) & \text{quando} \space y_i = 1 \\\\\\ -\log(1-\hat{y}_i) & \text{quando} \space y_i = 0 \\ \!\end{cases}$$` ] .pull-rigth[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-86-1.png" height="280" style="display: block; margin: auto;" /> ] --- # Regressão Logística - Custo Na regressão logística a estratégia é a mesma. Queremos a curva que **erre menos**. Exemplo: Modelo de regressão logística `\(f(x) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x)}}\)`. .pull-left[ <img src="static/img/gif_reg_logistica_otimizacao.gif" style="position: fixed; width: 35%; "> ] .pull-right[ Medida de Erro da Logística: `$$D = \frac{-1}{N}\sum[y_i \log\hat{y_i} + (1 - y_i )\log(1 - \hat{y_i})]$$` Em que `$$\hat{y}_i = f(x_i) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x_i)}}$$` ] --- ## Regressão Logística - Interpretação Os coeficientes da regressão logística representam mudanças percentuais nas **chances.** Exemplos: <br/> Spam: `\(\log\Bigg(\frac{p(\text{11 exc})}{1 - p(\text{11 exc})}\Bigg) - \log\Bigg(\frac{p(\text{10 exc})}{1 - p(\text{10 exc})}\Bigg) = \beta_1\)` <br/> Inadimplência: `\(\log\Bigg(\frac{p(\text{empregado})}{1 - p(\text{empregado})}\Bigg) - \log\Bigg(\frac{p(\text{desempregado})}{1 - p(\text{desempregado})}\Bigg) = \beta_1\)` --- ## Regressão Logística - Interpretação Os coeficientes da regressão logística representam mudanças percentuais nas **chances.** Exemplos: <br/> Spam: `\(\frac{p(\text{11 exc})}{1 - p(\text{11 exc})} = \frac{p(\text{10 exc})}{1 - p(\text{10 exc})} * e^{\beta_1}\)` <br/> Inadimplência: `\(\frac{p(\text{empregado})}{1 - p(\text{empregado})} = \frac{p(\text{desempregado})}{1 - p(\text{desempregado})} * e^{\beta_1}\)` --- ## Regressão Logística - Interpretação .letrinha[ ```r modelo <- glm(spam ~ pts_exclamacao, data = email_spam, family = binomial()) summary(modelo) ``` ``` ## ## Call: ## glm(formula = spam ~ pts_exclamacao, family = binomial(), data = email_spam) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.57362 -0.35481 0.06569 0.33189 2.42856 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) -5.758236 0.381050 -15.11 <2e-16 *** ## pts_exclamacao 0.040325 0.002567 15.71 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 1385.00 on 999 degrees of freedom ## Residual deviance: 574.33 on 998 degrees of freedom ## AIC: 578.33 ## ## Number of Fisher Scoring iterations: 6 ``` ] --- ## Regressão Logística - Interpretação `$$\log\Bigg(\frac{p(\text{11 exc})}{1 - p(\text{11 exc})}\Bigg) - \log\Bigg(\frac{p(\text{10 exc})}{1 - p(\text{10 exc})}\Bigg) = 0.040325$$` ou `$$\log\Bigg(\frac{\frac{p(\text{11 exc})}{1 - p(\text{11 exc})}}{\frac{p(\text{10 exc})}{1 - p(\text{10 exc})}}\Bigg) = 0.040325$$` ou... --- ## Regressão Logística - Interpretação `$$\frac{p(\text{11 exc})}{1 - p(\text{11 exc})} = \frac{p(\text{10 exc})}{1 - p(\text{10 exc})} * e^{0.040325}$$` ou `$$\frac{p(\text{11 exc})}{1 - p(\text{11 exc})} = \frac{p(\text{10 exc})}{1 - p(\text{10 exc})} * 1.04$$` Para cada exclamação a mais no e-mail, a chance de ser spam aumenta em 4%. --- ## Regressão Logística - Interpretação ```r gtsummary::tbl_regression(modelo) ``` <div id="xhyneqnlzm" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #xhyneqnlzm .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #xhyneqnlzm .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xhyneqnlzm .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #xhyneqnlzm .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 6px; border-top-color: #FFFFFF; border-top-width: 0; } #xhyneqnlzm .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xhyneqnlzm .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xhyneqnlzm .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #xhyneqnlzm .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #xhyneqnlzm .gt_column_spanner_outer:first-child { padding-left: 0; } #xhyneqnlzm .gt_column_spanner_outer:last-child { padding-right: 0; } #xhyneqnlzm .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #xhyneqnlzm .gt_group_heading { padding: 8px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #xhyneqnlzm .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #xhyneqnlzm .gt_from_md > :first-child { margin-top: 0; } #xhyneqnlzm .gt_from_md > :last-child { margin-bottom: 0; } #xhyneqnlzm .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #xhyneqnlzm .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #xhyneqnlzm .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xhyneqnlzm .gt_first_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #xhyneqnlzm .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xhyneqnlzm .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #xhyneqnlzm .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #xhyneqnlzm .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xhyneqnlzm .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xhyneqnlzm .gt_footnote { margin: 0px; font-size: 90%; padding: 4px; } #xhyneqnlzm .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xhyneqnlzm .gt_sourcenote { font-size: 90%; padding: 4px; } #xhyneqnlzm .gt_left { text-align: left; } #xhyneqnlzm .gt_center { text-align: center; } #xhyneqnlzm .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #xhyneqnlzm .gt_font_normal { font-weight: normal; } #xhyneqnlzm .gt_font_bold { font-weight: bold; } #xhyneqnlzm .gt_font_italic { font-style: italic; } #xhyneqnlzm .gt_super { font-size: 65%; } #xhyneqnlzm .gt_footnote_marks { font-style: italic; font-weight: normal; font-size: 65%; } </style> <table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>log(OR)</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>95% CI</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>p-value</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td class="gt_row gt_left">pts_exclamacao</td> <td class="gt_row gt_center">0.04</td> <td class="gt_row gt_center">0.04, 0.05</td> <td class="gt_row gt_center"><0.001</td></tr> </tbody> <tfoot> <tr class="gt_footnotes"> <td colspan="4"> <p class="gt_footnote"> <sup class="gt_footnote_marks"> <em>1</em> </sup> OR = Odds Ratio, CI = Confidence Interval <br /> </p> </td> </tr> </tfoot> </table> </div> ```r gtsummary::tbl_regression(modelo, exponentiate = TRUE) ``` <div id="kiedoxxznx" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #kiedoxxznx .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #kiedoxxznx .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #kiedoxxznx .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #kiedoxxznx .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 6px; border-top-color: #FFFFFF; border-top-width: 0; } #kiedoxxznx .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #kiedoxxznx .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #kiedoxxznx .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #kiedoxxznx .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #kiedoxxznx .gt_column_spanner_outer:first-child { padding-left: 0; } #kiedoxxznx .gt_column_spanner_outer:last-child { padding-right: 0; } #kiedoxxznx .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #kiedoxxznx .gt_group_heading { padding: 8px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #kiedoxxznx .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #kiedoxxznx .gt_from_md > :first-child { margin-top: 0; } #kiedoxxznx .gt_from_md > :last-child { margin-bottom: 0; } #kiedoxxznx .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #kiedoxxznx .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #kiedoxxznx .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #kiedoxxznx .gt_first_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #kiedoxxznx .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #kiedoxxznx .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #kiedoxxznx .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #kiedoxxznx .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #kiedoxxznx .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #kiedoxxznx .gt_footnote { margin: 0px; font-size: 90%; padding: 4px; } #kiedoxxznx .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #kiedoxxznx .gt_sourcenote { font-size: 90%; padding: 4px; } #kiedoxxznx .gt_left { text-align: left; } #kiedoxxznx .gt_center { text-align: center; } #kiedoxxznx .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #kiedoxxznx .gt_font_normal { font-weight: normal; } #kiedoxxznx .gt_font_bold { font-weight: bold; } #kiedoxxznx .gt_font_italic { font-style: italic; } #kiedoxxznx .gt_super { font-size: 65%; } #kiedoxxznx .gt_footnote_marks { font-style: italic; font-weight: normal; font-size: 65%; } </style> <table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>OR</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>95% CI</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>p-value</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td class="gt_row gt_left">pts_exclamacao</td> <td class="gt_row gt_center">1.04</td> <td class="gt_row gt_center">1.04, 1.05</td> <td class="gt_row gt_center"><0.001</td></tr> </tbody> <tfoot> <tr class="gt_footnotes"> <td colspan="4"> <p class="gt_footnote"> <sup class="gt_footnote_marks"> <em>1</em> </sup> OR = Odds Ratio, CI = Confidence Interval <br /> </p> </td> </tr> </tfoot> </table> </div> --- ## Regressão Logística - Interpretação ```r gtsummary::tbl_regression(churn) ``` <div id="xrmldmzvvw" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #xrmldmzvvw .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #xrmldmzvvw .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xrmldmzvvw .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #xrmldmzvvw .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 6px; border-top-color: #FFFFFF; border-top-width: 0; } #xrmldmzvvw .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xrmldmzvvw .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #xrmldmzvvw .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #xrmldmzvvw .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #xrmldmzvvw .gt_column_spanner_outer:first-child { padding-left: 0; } #xrmldmzvvw .gt_column_spanner_outer:last-child { padding-right: 0; } #xrmldmzvvw .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #xrmldmzvvw .gt_group_heading { padding: 8px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #xrmldmzvvw .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #xrmldmzvvw .gt_from_md > :first-child { margin-top: 0; } #xrmldmzvvw .gt_from_md > :last-child { margin-bottom: 0; } #xrmldmzvvw .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #xrmldmzvvw .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #xrmldmzvvw .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xrmldmzvvw .gt_first_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #xrmldmzvvw .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #xrmldmzvvw .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #xrmldmzvvw .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #xrmldmzvvw .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #xrmldmzvvw .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xrmldmzvvw .gt_footnote { margin: 0px; font-size: 90%; padding: 4px; } #xrmldmzvvw .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #xrmldmzvvw .gt_sourcenote { font-size: 90%; padding: 4px; } #xrmldmzvvw .gt_left { text-align: left; } #xrmldmzvvw .gt_center { text-align: center; } #xrmldmzvvw .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #xrmldmzvvw .gt_font_normal { font-weight: normal; } #xrmldmzvvw .gt_font_bold { font-weight: bold; } #xrmldmzvvw .gt_font_italic { font-style: italic; } #xrmldmzvvw .gt_super { font-size: 65%; } #xrmldmzvvw .gt_footnote_marks { font-style: italic; font-weight: normal; font-size: 65%; } </style> <table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>log(OR)</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>95% CI</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>p-value</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td class="gt_row gt_left">tempo_de_relacionamento</td> <td class="gt_row gt_center">-7.0</td> <td class="gt_row gt_center">-12, -3.0</td> <td class="gt_row gt_center">0.003</td></tr> <tr><td class="gt_row gt_left">idade</td> <td class="gt_row gt_center">-5.2</td> <td class="gt_row gt_center">-9.5, -2.0</td> <td class="gt_row gt_center">0.005</td></tr> </tbody> <tfoot> <tr class="gt_footnotes"> <td colspan="4"> <p class="gt_footnote"> <sup class="gt_footnote_marks"> <em>1</em> </sup> OR = Odds Ratio, CI = Confidence Interval <br /> </p> </td> </tr> </tfoot> </table> </div> ```r gtsummary::tbl_regression(churn, exponentiate = TRUE) ``` <div id="wwecphcpqm" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"> <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #wwecphcpqm .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #wwecphcpqm .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #wwecphcpqm .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #wwecphcpqm .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 6px; border-top-color: #FFFFFF; border-top-width: 0; } #wwecphcpqm .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #wwecphcpqm .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #wwecphcpqm .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #wwecphcpqm .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #wwecphcpqm .gt_column_spanner_outer:first-child { padding-left: 0; } #wwecphcpqm .gt_column_spanner_outer:last-child { padding-right: 0; } #wwecphcpqm .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 5px; overflow-x: hidden; display: inline-block; width: 100%; } #wwecphcpqm .gt_group_heading { padding: 8px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #wwecphcpqm .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #wwecphcpqm .gt_from_md > :first-child { margin-top: 0; } #wwecphcpqm .gt_from_md > :last-child { margin-bottom: 0; } #wwecphcpqm .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #wwecphcpqm .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #wwecphcpqm .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #wwecphcpqm .gt_first_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #wwecphcpqm .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #wwecphcpqm .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #wwecphcpqm .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #wwecphcpqm .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #wwecphcpqm .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #wwecphcpqm .gt_footnote { margin: 0px; font-size: 90%; padding: 4px; } #wwecphcpqm .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #wwecphcpqm .gt_sourcenote { font-size: 90%; padding: 4px; } #wwecphcpqm .gt_left { text-align: left; } #wwecphcpqm .gt_center { text-align: center; } #wwecphcpqm .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #wwecphcpqm .gt_font_normal { font-weight: normal; } #wwecphcpqm .gt_font_bold { font-weight: bold; } #wwecphcpqm .gt_font_italic { font-style: italic; } #wwecphcpqm .gt_super { font-size: 65%; } #wwecphcpqm .gt_footnote_marks { font-style: italic; font-weight: normal; font-size: 65%; } </style> <table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1"><strong>Characteristic</strong></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>OR</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>95% CI</strong><sup class="gt_footnote_marks">1</sup></th> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1"><strong>p-value</strong></th> </tr> </thead> <tbody class="gt_table_body"> <tr><td class="gt_row gt_left">tempo_de_relacionamento</td> <td class="gt_row gt_center">0.00</td> <td class="gt_row gt_center">0.00, 0.05</td> <td class="gt_row gt_center">0.003</td></tr> <tr><td class="gt_row gt_left">idade</td> <td class="gt_row gt_center">0.01</td> <td class="gt_row gt_center">0.00, 0.14</td> <td class="gt_row gt_center">0.005</td></tr> </tbody> <tfoot> <tr class="gt_footnotes"> <td colspan="4"> <p class="gt_footnote"> <sup class="gt_footnote_marks"> <em>1</em> </sup> OR = Odds Ratio, CI = Confidence Interval <br /> </p> </td> </tr> </tfoot> </table> </div> --- # Regressão Logística - Predições O "produto final" será um vetor de probabilidades estimadas. .pull-left[ <table> <thead> <tr> <th style="text-align:right;background-color: white !important;text-align: center;"> pts excl </th> <th style="text-align:left;background-color: white !important;text-align: center;"> classe observada </th> <th style="text-align:right;background-color: white !important;text-align: center;"> prob </th> <th style="text-align:left;background-color: white !important;text-align: center;"> classe predita </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;background-color: white !important;text-align: center;"> 167 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> 0.79 </td> <td style="text-align:left;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> Spam </td> </tr> <tr> <td style="text-align:right;background-color: white !important;text-align: center;"> 129 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> 0.45 </td> <td style="text-align:left;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> Não Spam </td> </tr> <tr> <td style="text-align:right;background-color: white !important;text-align: center;"> 299 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> 1.00 </td> <td style="text-align:left;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> Spam </td> </tr> <tr> <td style="text-align:right;background-color: white !important;text-align: center;"> 270 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> 1.00 </td> <td style="text-align:left;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> Spam </td> </tr> <tr> <td style="text-align:right;background-color: white !important;text-align: center;"> 187 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> 0.89 </td> <td style="text-align:left;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> Spam </td> </tr> <tr> <td style="text-align:right;background-color: white !important;text-align: center;"> 85 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> 0.12 </td> <td style="text-align:left;background-color: white !important;text-align: center;font-weight: bold;color: purple !important;"> Não Spam </td> </tr> </tbody> </table> ] .pull-right[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-95-1.png" style="display: block; margin: auto;" /> ] --- # Matriz de Confusão .pull-left[ <table class="table table-bordered" style="font-size: 20px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Neg </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Pos </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Neg </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> TN </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> FN </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Pos </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> FP </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> TP </td> </tr> </tbody> </table> <br/> <table class="table table-bordered" style="font-size: 20px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: red !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="1"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">p > 50%</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Não Spam </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Spam </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 410 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 73 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 52 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 465 </td> </tr> </tbody> </table> ] .pull-right[ $$ \begin{array}{lcc} \mbox{accuracy} & = & \frac{TP + TN}{TP + TN + FP + FN}\\\\ & & \\\\ \mbox{precision} & = & \frac{TP}{TP + FP}\\\\ & & \\\\ \mbox{recall/TPR} & = & \frac{TP}{TP + FN} \\\\ & & \\\\ \mbox{F1 score} & =& \frac{2}{1/\mbox{precision} + 1/\mbox{recall}}\\\\ & & \\\\ \mbox{FPR} & = & \frac{FP}{FP + TN} \end{array} $$ ] --- # Nota de Corte (Threshold) .pull-left[ <table class="table table-bordered" style="font-size: 16px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: red !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="1"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">p > 10%</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Não Spam </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Spam </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 267 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 8 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 195 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 530 </td> </tr> </tbody> </table> <table class="table table-bordered" style="font-size: 16px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: red !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="1"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">p > 25%</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Não Spam </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Spam </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 332 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 28 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 130 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 510 </td> </tr> </tbody> </table> <table class="table table-bordered" style="font-size: 16px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: red !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="1"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">p > 50%</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Não Spam </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Spam </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 410 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 73 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 52 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 465 </td> </tr> </tbody> </table> ] .pull-right[ <table class="table table-bordered" style="font-size: 16px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: red !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="1"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">p > 75%</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Não Spam </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Spam </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 443 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 112 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 19 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 426 </td> </tr> </tbody> </table> <table class="table table-bordered" style="font-size: 16px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: red !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="1"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">p > 90%</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; color: black !important;padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Não Spam </th> <th style="text-align:right;background-color: white !important;text-align: center;"> Spam </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Não Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 456 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 171 </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Spam </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 3in; "> 6 </td> <td style="text-align:right;background-color: white !important;text-align: center;width: 2in; "> 367 </td> </tr> </tbody> </table> ] --- # Curva ROC .pull-left[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-101-1.png" style="display: block; margin: auto;" /> [An introduction to ROC analysis](https://people.inf.elte.hu/kiss/11dwhdm/roc.pdf) ] .pull-right[ <br/> <table class="table table-bordered" style="font-size: 20px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Neg </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Pos </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Neg </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> TN </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> FN </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Pos </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> FP </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> TP </td> </tr> </tbody> </table> $$ \begin{array}{lcc} \mbox{TPR} & = & \frac{TP}{TP + FN} \\\\ & & \\\\ \mbox{FPR} & = & \frac{FP}{FP + TN} \end{array} $$ ] --- # Curva ROC - Métrica AUC .pull-left[ <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-103-1.png" style="display: block; margin: auto;" /> [An introduction to ROC analysis](https://people.inf.elte.hu/kiss/11dwhdm/roc.pdf) ] .pull-right[ <br/> <table class="table table-bordered" style="font-size: 20px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Neg </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Pos </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Neg </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> TN </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> FN </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> Pos </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> FP </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> TP </td> </tr> </tbody> </table> $$ \mbox{AUC} = \mbox{Area Under The ROC Curve} $$ ] **PS:** AUC varia de 0.5 a 1.0. O que significa se AUC for zero? --- # Curva ROC - Playground <a href = "http://arogozhnikov.github.io/2015/10/05/roc-curve.html"> <img src="static/img/roc_curve.gif" style=" display: block; margin-left: auto; margin-right: auto;"></img> </a> --- # Múltiplas Notas de Corte .pull-left[ Risco por Segmentação <table class="table table-bordered" style="font-size: 20px; width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; padding-right: 4px; padding-left: 4px; background-color: white !important;" colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">Observado</div></th> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> </tr> <tr> <th style="text-align:left;background-color: white !important;text-align: center;"> Predito </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Neg </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Pos </th> <th style="text-align:left;background-color: white !important;text-align: center;"> N </th> <th style="text-align:left;background-color: white !important;text-align: center;"> Risco </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> A (até 0,19) </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> 90 </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> 11 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 101 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 11% </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> B (até 0,44) </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> 60 </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> 40 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 100 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 40% </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> C (até 0,62) </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> 39 </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> 60 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 99 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 60% </td> </tr> <tr> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; font-weight: bold;"> D (0,62 ou +) </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 3in; "> 20 </td> <td style="text-align:left;background-color: white !important;text-align: center;width: 2in; "> 80 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 100 </td> <td style="text-align:left;background-color: white !important;text-align: center;"> 80% </td> </tr> </tbody> </table> ] .pull-right-letrinha[ Usamos o `score` como preferirmos ```r dados %>% mutate( segmento = case_when( score < 0.19 ~ "A", score < 0.44 ~ "B", score < 0.62 ~ "C", score >= 0.62 ~ "D" ) ) ``` ] <img src="02-intro-regressao-linear_files/figure-html/unnamed-chunk-107-1.png" width="800" style="display: block; margin: auto;" /> --- class: middle, center, inverse # Tópicos para próximos passos --- ## (Opcional) Abordagem Probabilística Do ponto de vista probabilístico, modela-se o problema como uma amostra de N indivíduos, todos independentes entre si e com distribuição Normal. $$ Y_i|x_i \sim N(\mu_i, \sigma^2), \space i = 1, \dots, N $$ E então, supõem que a média de `\(Y\)` dado o valor de `\(x\)` seja linear: $$ \mu = E[Y|x] = \beta_0 + \beta_1x $$ Assim, gostaríamos de achar `\(\beta_0\)` e `\(\beta_1\)` que fizessem dessa amostra a mais verossímil possível. Daí entra o conceito de verossimilhança, que é a probabilidade conjunta dos dados acontecerem: $$ P(Y_1, \dots, Y_N|x) \overset{\text{indep}}{=} P(Y_1|x_1)P(Y_2|x_2)\dots P(Y_N|x_N) $$ continua... --- ## (Opcional) Abordagem Probabilística Se tirarmos o `\(logarítmo\)` dessa probabilidade conjunta, teremos: $$ logP(Y_1, \dots, Y_N|x) \overset{\text{indep}}{=} logP(Y_i|x_1) + log P(Y_2|x_2) +\dots +logP(Y_N|x_N) $$ Que podemos escrever de forma mais sussinta usando um somatório: `$$\ell = logP(Y_1, \dots, Y_N|x) = \sum_{i = 1}^{N}logP(Y_i|x_i)$$` Essa expressão que chamamos de `\(\ell\)` é conhecida como log-verossimilhança (log-likelihood no inglês). continua... --- ## (Opcional) Abordagem Probabilística Já que assumimos que `\(Y_i|x_i\)` segue uma distribuição `\(N(\beta_0 + \beta_1x_i, \sigma^2)\)`, temos que: $$ \ell = \sum_{i = 1}^{N}log\left(\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left[-\frac{1}{2\sigma^2}(y_i - \mu_i)^2 \right] \right) $$ Que depois de simplificar (e deixando as constantes de fora), fica `$$\ell = -\frac{1}{N}\sum(y_i - \mu_i)^2 = -\frac{1}{N}\sum(y_i - \color{red}{(\beta_0 + \beta_1speed)})^2 = -EQM$$` Ou seja, maximizar a verossimilhança é equivalente a minimizar o EQM como vínhamos fazendo. --- ## Questões importantes Questões que usualmente estamos interessados quando ajustamos uma regressão linear. - Pelo menos um dos preditores `\(X1, X2,\dots,X_p\)` é útil para prever/explicar? - Todos os preditores são úteis ou apenas um subconjunto deles que é? - O quão bem o modelo se ajusta aos dados? .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 75 (Some Important Questions). ] --- ## Sobreajuste (overfitting) Modelo real é de **grau 3** 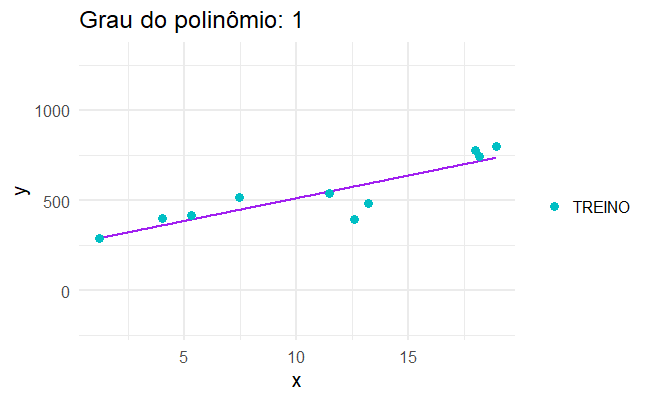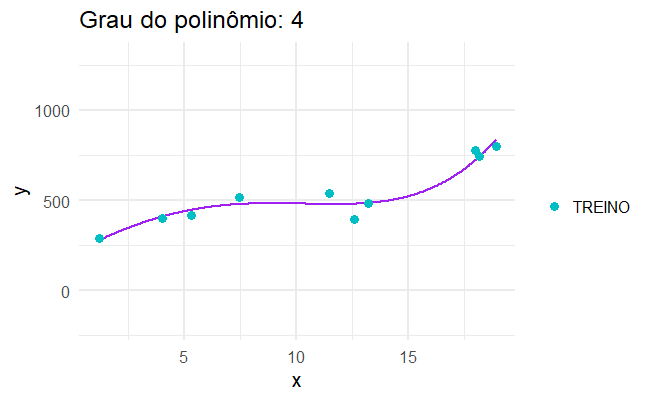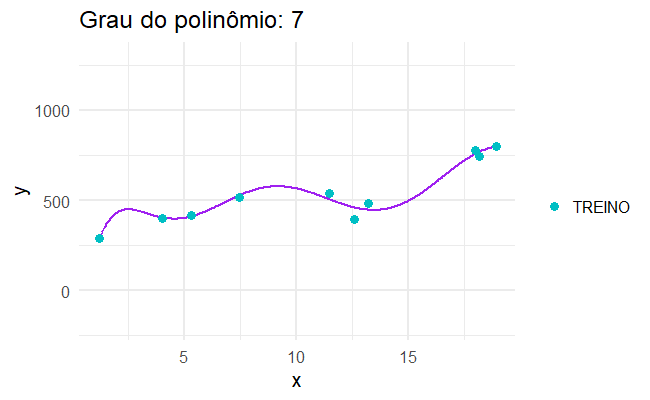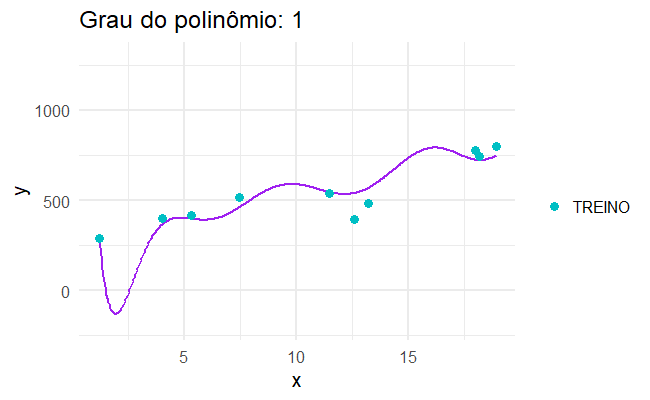 --- ## Sobreajuste (overfitting) Modelo real é de **grau 3**  --- ## Sobreajuste (overfitting) Modelo real é de **grau 3**  .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 61 (Simple Linear Regression). ] --- ## Regularização Relembrando o nossa **função de custo** EQM. `$$EQM = \frac{1}{N}\sum(y_i - \hat{y_i})^2 = \frac{1}{N}\sum(y_i - \color{red}{(\hat{\beta}_0 + \hat{\beta}_1x_{1i} + \dots + \hat{\beta}_px_{pi})})^2$$` Regularizar é "não deixar os `\(\beta's\)` soltos demais". `$$EQM_{regularizado} = EQM + \color{red}{\lambda}\sum_{j = 1}^{p}|\beta_j|$$` Ou seja, **penalizamos** a função de custo se os `\(\beta's\)` forem muito grandes. .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 203 (Linear Model Selection and Regularization). ] --- ## LASSO e Seleção de Preditores Conforme aumentamos o `\(\color{red}{\lambda}\)`, forçamos os `\(\beta's\)` a serem cada vez menores.  .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 219 (The LASSO). ] --- ## LASSO e Seleção de Preditores Conforme aumentamos o `\(\lambda\)`, forçamos os `\(\beta's\)` a serem cada vez menores.  .footnote[ Ver [ISL](https://www.ime.unicamp.br/~dias/Intoduction%20to%20Statistical%20Learning.pdf) página 219 (The LASSO). ] --- ## Validação Cruzada ``` ## # 5-fold cross-validation ## # A tibble: 5 × 6 ## splits id n_treino n_teste regressao eqm_teste ## <list> <chr> <dbl> <dbl> <list> <dbl> ## 1 <split [40/10]> Fold1 40 10 <lm> 17.2 ## 2 <split [40/10]> Fold2 40 10 <lm> 13.8 ## 3 <split [40/10]> Fold3 40 10 <lm> 12.4 ## 4 <split [40/10]> Fold4 40 10 <lm> 21.2 ## 5 <split [40/10]> Fold5 40 10 <lm> 9.13 ``` ``` ## [1] 14.73 ``` ERRO DE VALIDAÇÃO CRUZADA: `$$EQM_{cv} = \frac{1}{10}\sum_{i=1}^{10}EQM_{Fold_i} = 14,671$$` --- ## Validação Cruzada <table> <thead> <tr> <th style="text-align:left;"> fold </th> <th style="text-align:right;"> speed </th> <th style="text-align:right;"> dist </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;background-color: #F8766D !important;"> fold 1 </td> <td style="text-align:right;background-color: #F8766D !important;"> 4 </td> <td style="text-align:right;background-color: #F8766D !important;"> 2 </td> </tr> <tr> <td style="text-align:left;background-color: #F8766D !important;"> fold 1 </td> <td style="text-align:right;background-color: #F8766D !important;"> 4 </td> <td style="text-align:right;background-color: #F8766D !important;"> 10 </td> </tr> <tr> <td style="text-align:left;background-color: #D39200 !important;"> fold 2 </td> <td style="text-align:right;background-color: #D39200 !important;"> 7 </td> <td style="text-align:right;background-color: #D39200 !important;"> 4 </td> </tr> <tr> <td style="text-align:left;background-color: #D39200 !important;"> fold 2 </td> <td style="text-align:right;background-color: #D39200 !important;"> 7 </td> <td style="text-align:right;background-color: #D39200 !important;"> 22 </td> </tr> <tr> <td style="text-align:left;background-color: #93AA00 !important;"> fold 3 </td> <td style="text-align:right;background-color: #93AA00 !important;"> 8 </td> <td style="text-align:right;background-color: #93AA00 !important;"> 16 </td> </tr> <tr> <td style="text-align:left;background-color: #93AA00 !important;"> fold 3 </td> <td style="text-align:right;background-color: #93AA00 !important;"> 9 </td> <td style="text-align:right;background-color: #93AA00 !important;"> 10 </td> </tr> <tr> <td style="text-align:left;background-color: #00BA38 !important;"> fold 4 </td> <td style="text-align:right;background-color: #00BA38 !important;"> 10 </td> <td style="text-align:right;background-color: #00BA38 !important;"> 18 </td> </tr> <tr> <td style="text-align:left;background-color: #00BA38 !important;"> fold 4 </td> <td style="text-align:right;background-color: #00BA38 !important;"> 10 </td> <td style="text-align:right;background-color: #00BA38 !important;"> 26 </td> </tr> <tr> <td style="text-align:left;background-color: #00C19F !important;"> fold 5 </td> <td style="text-align:right;background-color: #00C19F !important;"> 10 </td> <td style="text-align:right;background-color: #00C19F !important;"> 34 </td> </tr> <tr> <td style="text-align:left;background-color: #00C19F !important;"> fold 5 </td> <td style="text-align:right;background-color: #00C19F !important;"> 11 </td> <td style="text-align:right;background-color: #00C19F !important;"> 17 </td> </tr> </tbody> </table> --- ## Limitações da Regressão Linear - Variável resposta Não Normal - Variável resposta Positiva - Variável resposta com mais de duas categorias - Relação funcional não linear entre X e Y - Muitas variáveis disponíveis - Muitas interações para testar entre as preditoras