Modelagem com {tidymodels}
Café Com Dados - Turnover com {tidymodels}
Source:vignettes/cafe_com_dados_modelage.Rmd
cafe_com_dados_modelage.Rmdlibrary(tictoc) library(pROC) library(vip) library(tidymodels) # ML framework library(cafecomdados) library(knitr) library(patchwork) theme_set(theme_light(18))
Base de treino/teste
set.seed(1) split_inicial <- initial_split(turnover, strata = "desligado")
Dataprep
library(embed) receita <- recipe(desligado ~ ., training(split_inicial)) %>% step_mutate( aleatorio = runif(n()) ) %>% step_corr(all_numeric()) %>% step_zv(all_predictors()) %>% step_normalize(all_numeric()) %>% step_woe(area, outcome = "desligado") %>% step_dummy(all_nominal(), -all_outcomes())
Olhadela na base processada:
baked <- bake(prep(receita), new_data = NULL) glimpse(baked) #> Rows: 11,250 #> Columns: 12 #> $ nivel_satisfacao <dbl> -0.4557996, -2.0306350, 0.4325692, … #> $ ultima_avaliacao <dbl> 0.8531845, 0.9704919, 0.9118382, -1… #> $ atuacao_projetos <dbl> 0.9788272, 2.6032269, 0.9788272, -1… #> $ horas_trabalhadas <dbl> 1.2270198, 1.4271830, 0.4463834, -0… #> $ tempo_empresa <dbl> 1.7214017, 0.3487704, 1.0350860, -0… #> $ desligado <fct> sim, sim, sim, sim, sim, sim, sim, … #> $ aleatorio <dbl> -0.05722123, 0.26993721, 0.13882900… #> $ woe_area <dbl> 0.05062382, 0.05062382, 0.05062382,… #> $ licenca_medica_não.licenciado <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,… #> $ promocao_ultimos_3_anos_promovido <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,… #> $ salario_baixo <dbl> 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,… #> $ salario_mediano <dbl> 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
Modelo
especificação da f(x)
Definir:
- A \(f(x)\): random forest, regressão, xgboost, redes neurais, etc.
- O modo (ou tarefa):
classificationouregression - A engine: pacote do R que vai ajustar o modelo.
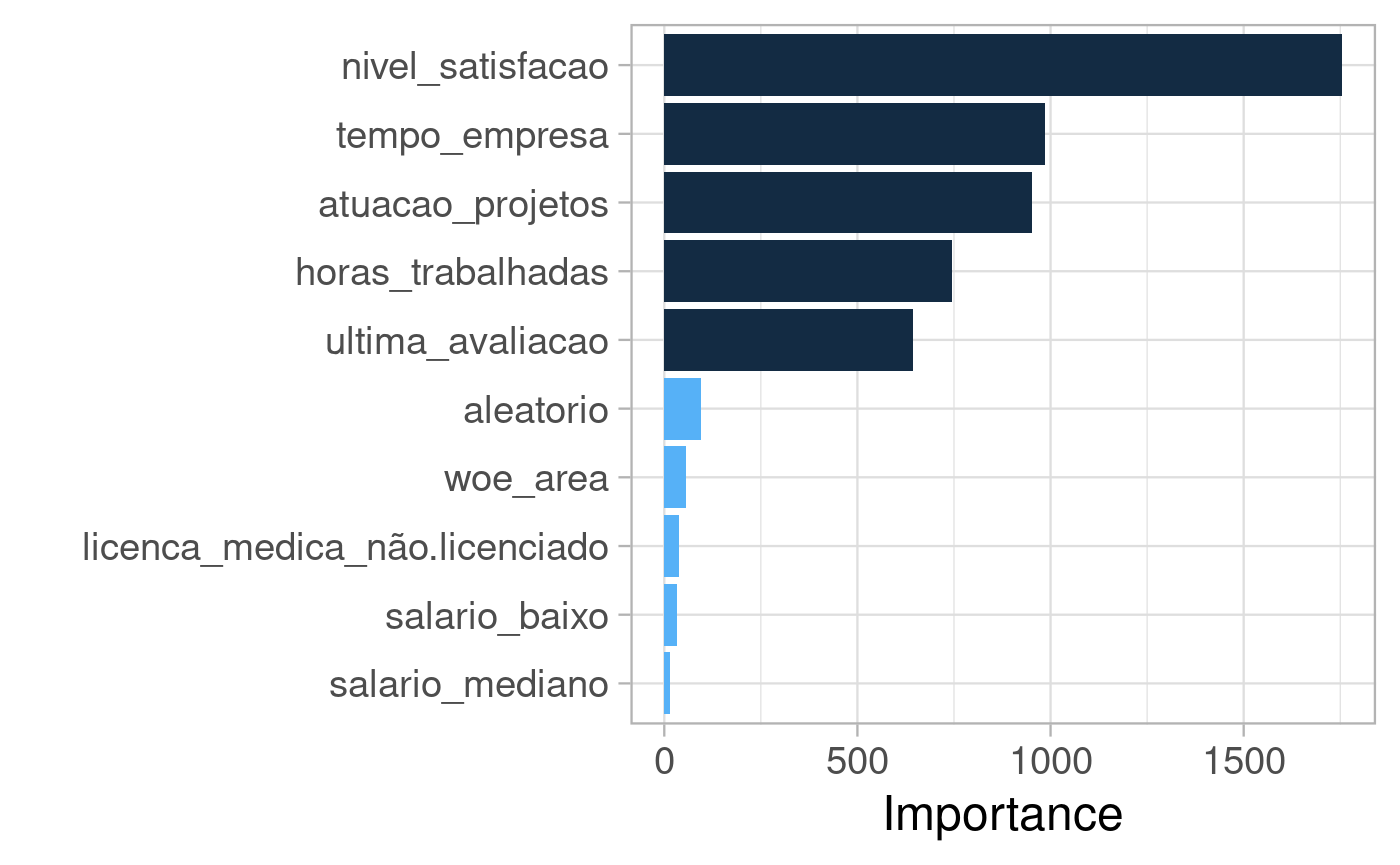
modelo <- rand_forest( trees = 300, mtry = tune(), min_n = tune() ) %>% set_mode("classification") %>% set_engine("ranger", importance = "impurity", num.threads = 8)
Workflow
Um workflow é um objeto que une o modelo com a receita.
wf <- workflow() %>% add_model(modelo) %>% add_recipe(receita) wf #> ══ Workflow ════════════════════════════════════════════════════════════════════ #> Preprocessor: Recipe #> Model: rand_forest() #> #> ── Preprocessor ──────────────────────────────────────────────────────────────── #> 6 Recipe Steps #> #> ● step_mutate() #> ● step_corr() #> ● step_zv() #> ● step_normalize() #> ● step_woe() #> ● step_dummy() #> #> ── Model ─────────────────────────────────────────────────────────────────────── #> Random Forest Model Specification (classification) #> #> Main Arguments: #> mtry = tune() #> trees = 300 #> min_n = tune() #> #> Engine-Specific Arguments: #> importance = impurity #> num.threads = 8 #> #> Computational engine: ranger
Tunagem de hiperparâmetros
Objetivo: achar o melhor par de valores dos hiperparâmertros. Neste exemplo, para mtry e min_n.
Reamostragens
Estratégia de reamostragens: cross-validation, bootstrap, etc. No exemplo será cross-validation com 3 folds.
# 5 folds de cross-validation set.seed(1) reamostragens <- vfold_cv(training(split_inicial), v = 3)
Grid de hiperparâmetros (opcional)
grade <- expand.grid( mtry = c(1, 2, 3, 5), min_n = 2^c(2, 4, 6) )
Avaliações
# gráfico autoplot(tunagem)
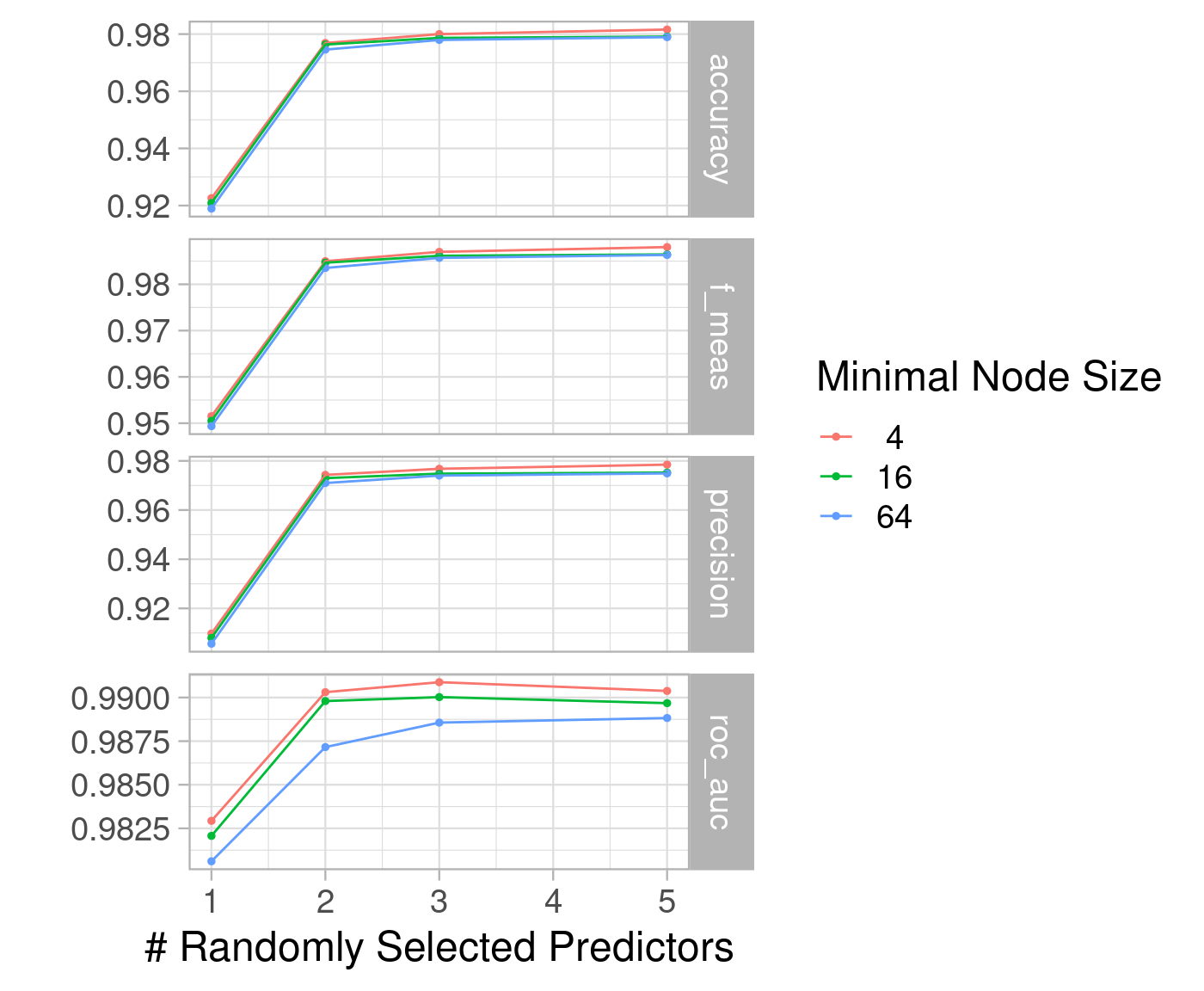
# tabela show_best(tunagem, "roc_auc") %>% kable(digits = 3)
| mtry | min_n | .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|---|---|
| 3 | 4 | roc_auc | binary | 0.991 | 3 | 0.002 | Model03 |
| 5 | 4 | roc_auc | binary | 0.990 | 3 | 0.002 | Model04 |
| 2 | 4 | roc_auc | binary | 0.990 | 3 | 0.002 | Model02 |
| 3 | 16 | roc_auc | binary | 0.990 | 3 | 0.002 | Model07 |
| 2 | 16 | roc_auc | binary | 0.990 | 3 | 0.002 | Model06 |
Desempenho do modelo final
Hora de ajustar o modelo na base de treino e avaliar na base de teste para reportar o desempenho esperado.
Atualização do workflow
atualiza o workflow com os hiperparametros encontrados
wf <- wf %>% finalize_workflow(select_best(tunagem, "roc_auc")) wf #> ══ Workflow ════════════════════════════════════════════════════════════════════ #> Preprocessor: Recipe #> Model: rand_forest() #> #> ── Preprocessor ──────────────────────────────────────────────────────────────── #> 6 Recipe Steps #> #> ● step_mutate() #> ● step_corr() #> ● step_zv() #> ● step_normalize() #> ● step_woe() #> ● step_dummy() #> #> ── Model ─────────────────────────────────────────────────────────────────────── #> Random Forest Model Specification (classification) #> #> Main Arguments: #> mtry = 3 #> trees = 300 #> min_n = 4 #> #> Engine-Specific Arguments: #> importance = impurity #> num.threads = 8 #> #> Computational engine: ranger
Ajuste
# last fit ajuste_final <- last_fit(wf, split_inicial, metrics = metric_set(accuracy, roc_auc, f_meas, specificity, precision, recall)) # métricas de desempenho collect_metrics(ajuste_final) #> # A tibble: 6 x 3 #> .metric .estimator .estimate #> <chr> <chr> <dbl> #> 1 accuracy binary 0.983 #> 2 f_meas binary 0.989 #> 3 spec binary 0.935 #> 4 precision binary 0.980 #> 5 recall binary 0.999 #> 6 roc_auc binary 0.996
# predicoes predicoes_na_base_teste <- collect_predictions(ajuste_final) # curva roc roc <- predicoes_na_base_teste %>% roc_curve(desligado, .pred_não) %>% autoplot() # curva de lift lift <- predicoes_na_base_teste %>% lift_curve(desligado, .pred_não) %>% autoplot() # KS ks <- predicoes_na_base_teste %>% ggplot(aes(x = .pred_sim, colour = desligado)) + stat_ecdf(show.legend = FALSE) # distribuicao dist <- predicoes_na_base_teste %>% ggplot(aes(x = .pred_sim, fill = desligado)) + geom_density() + theme(axis.title = element_blank()) (roc + lift)/(ks + dist)
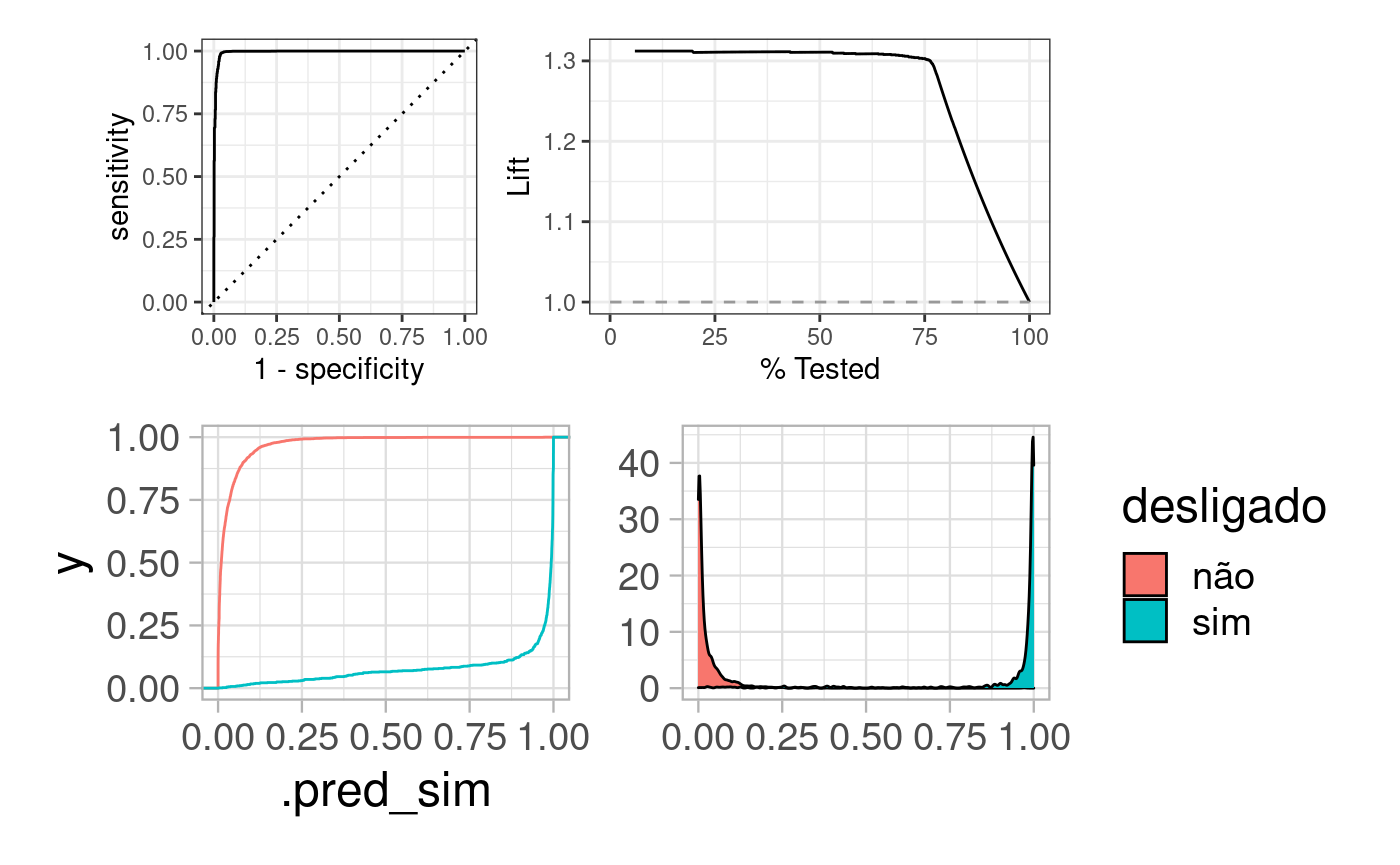
Modelo final
Efeito marginal (com ICE customizado)
library(prediction) # ICE ice_df <- function(data, var) { baked <- bake(extract_recipe(modelo_final), data) %>% rowid_to_column("id") cols <- c(setdiff(names(baked), names(data)), "id") data <- data %>% left_join(baked %>% select(all_of(cols)), by = "id") var_str <- rlang::as_name(rlang::enquo(var)) var_vec <- data %>% pull({{var}}) var_vec_unique <- unique(var_vec) n_distincts <- length(var_vec_unique) sequencia_ice <- if(n_distincts > 20) seq_range(var_vec_unique[var_vec_unique < quantile(var_vec_unique, 0.9)], 20) else var_vec_unique grid <- data %>% tidyr::expand(id, {{var}} := sequencia_ice) data <- data %>% dplyr::select(-{{var}}) %>% left_join(grid, by = "id") %>% mutate( pred = predict(modelo_final, new_data = ., type = "prob")$.pred_sim, variavel = var_str, sequencia_ice = {{var}} ) if(!is.numeric(data$sequencia_ice)) data$sequencia_ice <- as.numeric(factor(data$sequencia_ice)) data } ice_df_full <- bind_rows( testing(split_inicial) %>% rowid_to_column("id") %>% ice_df(nivel_satisfacao), testing(split_inicial) %>% rowid_to_column("id") %>% ice_df(tempo_empresa), testing(split_inicial) %>% rowid_to_column("id") %>% ice_df(aleatorio), testing(split_inicial) %>% rowid_to_column("id") %>% ice_df(atuacao_projetos), testing(split_inicial) %>% rowid_to_column("id") %>% ice_df(horas_trabalhadas), testing(split_inicial) %>% rowid_to_column("id") %>% ice_df(ultima_avaliacao) ) ice_df_full %>% ggplot(aes(x = sequencia_ice, y = pred)) + geom_line(alpha = 0.01, aes(group = id)) + stat_smooth(se = FALSE) + stat_summary(se = FALSE, geom = "point", fun = "mean") + facet_wrap(~variavel, scales = "free_x")
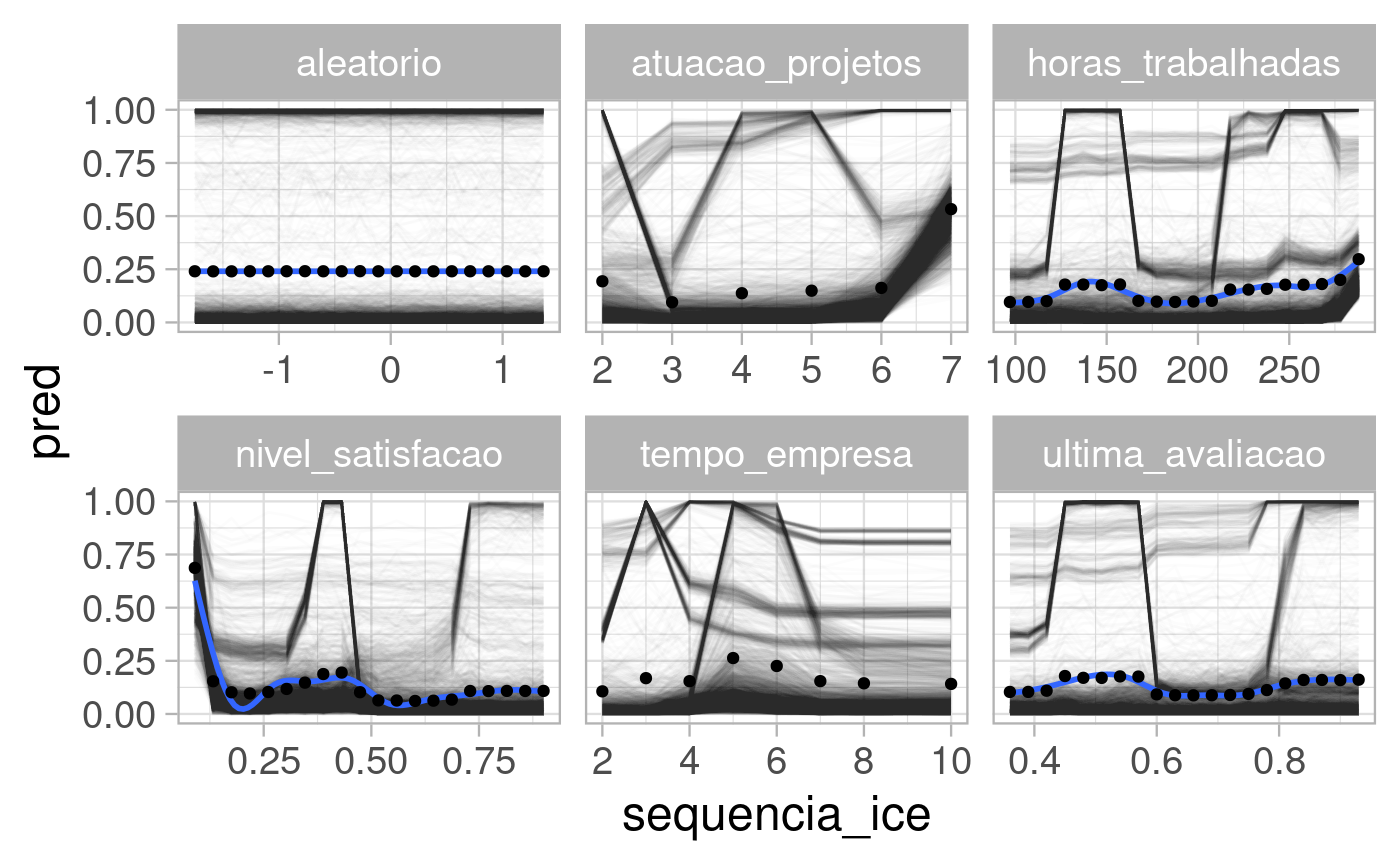
Predição
novo_funcionario <- data.frame( nivel_satisfacao = 0.5, ultima_avaliacao = 0.9, atuacao_projetos = 4, horas_trabalhadas = 220, tempo_empresa = 1, licenca_medica = "não licenciado", promocao_ultimos_3_anos = "não promovido", area = "comercial", salario = "baixo" ) predict(modelo_final, new_data = novo_funcionario, type = "prob") #> # A tibble: 1 x 2 #> .pred_não .pred_sim #> <dbl> <dbl> #> 1 0.988 0.0117
Armazenamento
usethis::use_data(modelo_final, overwrite = TRUE)